Tesseract Vs EasyOcr
- General
Tesseract Vs EasyOcr
In this article, we will use and compare the accuracy of Tesseract and EasyOcr as free popular OCR Engines.
WHY DO WE NEED OCR
Optical Character Recognition (OCR) becomes more popular as document digitalization evolves. More and more companies are looking for automating documentation, and OCR plays a vital role in processing image-based documents. Common use-cases are:
- Extracting text from Pictures
- Converting handwritten messages or notes
GETTING STARTED WITH TESSERACT OCR
The following steps would guide you through setting up Tesseract on linux, performing ocr action on images.
1. Installing Tesseract
To install Tesseract on Debian or Ubuntu Linux distribution, use apt as shown below
|
1 |
apt-get install tesseract-ocr |
2. Installing Language (Optional)
|
1 |
apt-get install tesseract-ocr-all |
Usually, the tesseract comes with the english pack by default if you want all the language packs to be downloaded, you can run the following command.
3. Usage
|
1 |
tesseract imagename outputbase [-l lang] [--oem ocrenginemode] [--psm pagesegmode] [configfiles...] |
|
1 |
tesseract /home/auriga/Desktop/picture.png stdout |
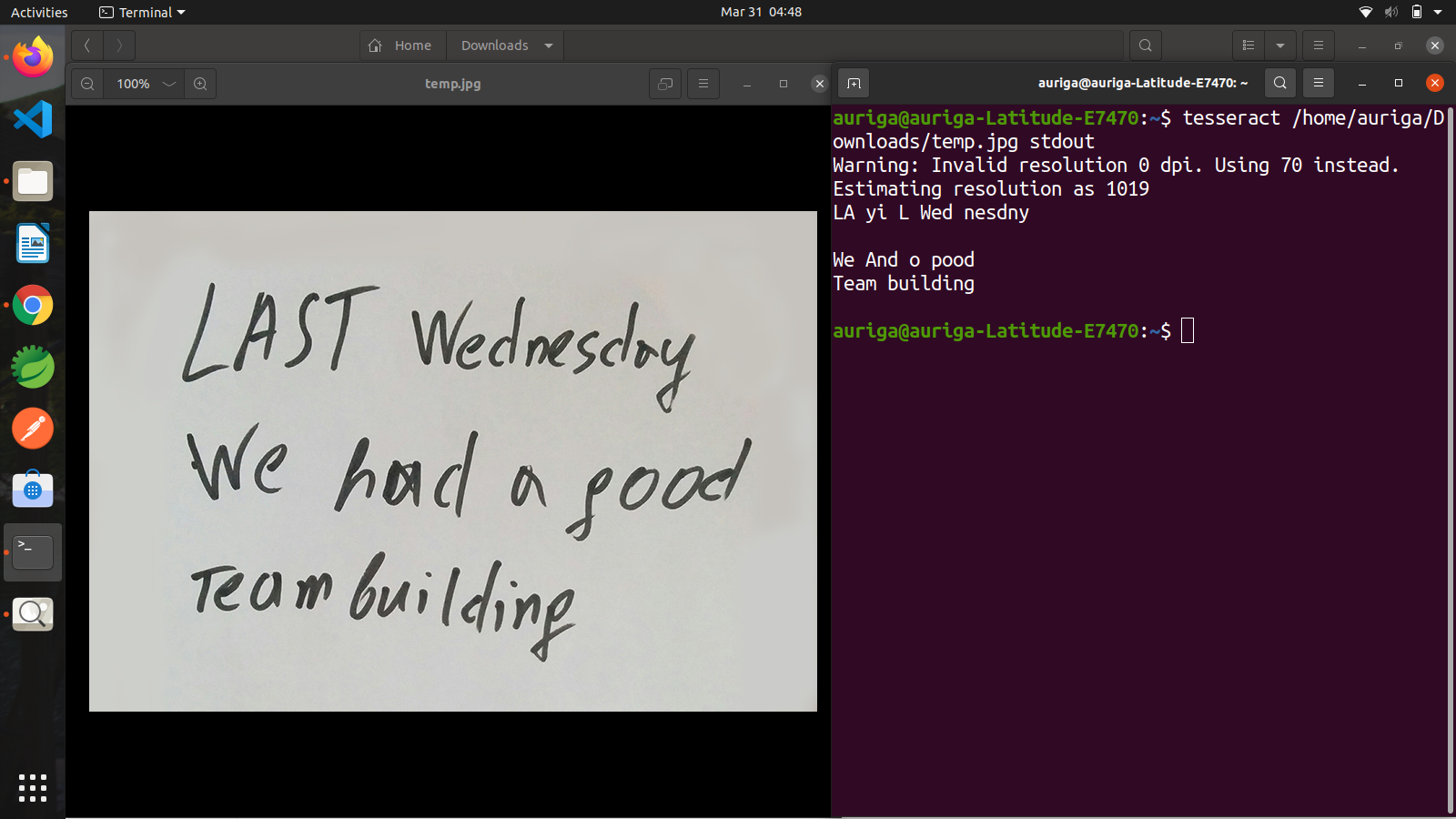
For more options like language, order, segmentation modes.
https://tesseract-ocr.github.io/tessdoc/Command-Line-Usage.html
4. Language Specific Wrapper
Tess4j:
A Java JNA wrapper for Tesseract OCR API. Tess4J is released and distributed under the Apache License, v2.0 and is also available from Maven Central Repository.
Maven Dependency:
|
1 2 3 4 5 |
<dependency> <groupId>net.sourceforge.tess4j</groupId> <artifactId>tess4j</artifactId> <version>5.2.0</version> </dependency> |
Features:
The library provides optical character recognition (OCR) support for:
- TIFF, JPEG, GIF, PNG, and BMP image formats
- Multi-page TIFF images
- PDF document format
PYTESSERACT:
Python-tesseract is a wrapper for Google’s Tesseract-OCR Engine. It is also useful as a stand-alone invocation script to tesseract.
Pip Installation:
|
1 |
pip install pytesseract |
|
1 |
pip install -U git+https://github.com/madmaze/pytesseract.git |
Features:
The library provides optical character recognition (OCR) support for:
- It can read all image types supported by the Pillow and Leptonica imaging libraries, including jpeg, png, gif, bmp, tiff, and others.
- Additionally, if used as a script, Python-tesseract will print the recognized text instead of writing it to a file.
GETTING STARTED WITH EasyOCR
The following steps would guide you through setting up EasyOCR on linux, performing ocr action on images.
Pre-Requisite: You need Python and PyTorch pre-installed for further process.
1. Installing Pip
To install pip package manager on Debian or Ubuntu Linux distribution, use apt as shown below
|
1 |
apt install python3-pip |
2. Installing EasyOCR
To install EasyOCR on Debian or Ubuntu Linux distribution, use pip as shown below
|
1 |
pip install easyocr |
Or
|
1 |
pip install git+git://github.com/jaidedai/easyocr.git |
2. Usage
|
1 |
easyocr -l en --detail 0 --paragraph True -f image.png |
For example OCR an image and printing on console
|
1 |
easyocr -l en --detail 0 -f /home/auriga/Downloads/temp.jpg |
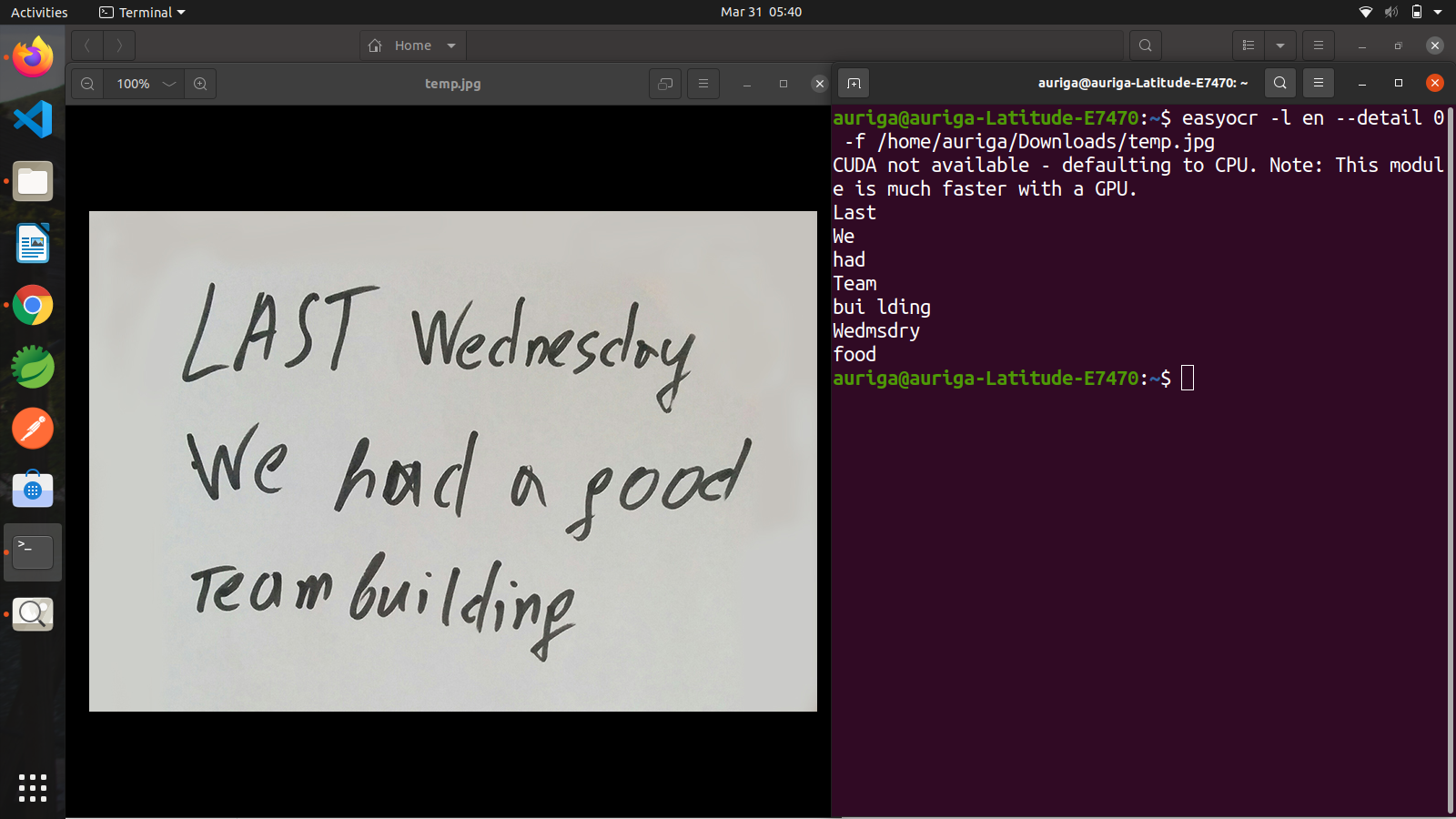
For more options like language list, detector, recognizer, etc.
https://www.jaided.ai/easyocr/documentation/
Conclusions
As per my testing,
- Tesseract is preferable for CPU wheras EasyOCR for GPU machine.
- Tesseract works better on character level, while EasyOCR does a better job on words.
Related content

Auriga: Leveling Up for Enterprise Growth!
Auriga’s journey began in 2010 crafting products for India’s