Kafka : Real-Time Data Streaming in Spring Boot (KRaft)
Kafka : Real-Time Data Streaming in Spring Boot (KRaft)
An open-source distributed streaming platform, Kafka enables real-time processing of large volumes of data.
It’s design enables it to handle data streams in a scalable, fault-tolerant, and durable way, allowing it to support applications in publishing and subscribing to streams of records, much like a message queue or enterprise messaging system. It optimizes for high-throughput, low-latency data streaming, making it ideal for use cases such as real-time analytics, data processing, and event-driven architectures.
Kafka is based on a distributed publish-subscribe model where it organizes data into topics and partitions it across multiple nodes in a cluster. This enables Kafka to provide horizontal scalability, fault tolerance, and high availability. It also provides features such as message retention, data replication, and support for multiple client libraries and programming languages out of which here we will be implementing it on JAVA (Spring Boot).
When to use Kafka ?
Some common use cases of Kafka include :
- Messaging: Applications can use it as a messaging system to decouple themselves and enable asynchronous communication between them. Applications can produce and consume messages from Kafka topics without being aware of each other’s existence.
- Log aggregation: It can collect and store log data from multiple sources, such as web servers, application servers, and databases. This enables centralized log management, analysis, and monitoring.
- Real-time processing: It’s fast and scalable architecture makes it ideal for real-time processing of large volumes of data. Users can use Kafka Streams, a Kafka client library, to process data streams in real-time and generate insights and analytics.
- Event-driven architectures: Companies can use it as the backbone of event-driven architectures, where events trigger actions. It’s support for pub-sub messaging and distributed processing makes it an ideal platform for building event-driven systems.
- Micro-services: It enables communication between micro-services in a distributed system. Each micro-service can publish and consume messages from Kafka topics, making it easy to build loosely coupled and scalable architectures.
Implementing Kafka in Spring Boot project :
Before starting with implementation let’s clear some basics.
Earlier Kafka used to rely on ZooKeeper for its working. However, managing ZooKeeper can be complex and time-consuming, moreover one needs to start ZooKeeper services separately to get started which has led to the development of KRaft.
With KRaft, Kafka nodes coordinate with each other directly, eliminating the need for a separate ZooKeeper cluster. This simplifies the deployment and management of Kafka clusters, as well as improves their stability and availability.
Some benefits of using KRaft include:
- Simplified deployment
- Improved stability and availability
- Reduced maintenance
- Lower operational costs
More about KRaft can be read from their official website : https://developer.confluent.io/learn/kraft/
Setting up system for development :
- Download Kafka from their official website : https://dlcdn.apache.org/kafka/
- Extract the file :
12tar -xzf <your_kafka_file>cd <extracted_kafka_file>
- Start Kafka environment :
Now we are in ready to go condition to use Kafka in our project.123KAFKA_CLUSTER_ID="$(bin/kafka-storage.sh random-uuid)"bin/kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c config/kraft/server.propertiesbin/kafka-server-start.sh config/kraft/server.properties
More about setup can be read from their official website : https://kafka.apache.org/quickstart#quickstart_download
Creating a Spring-Boot project :
NOTE : Make sure you use Java 8+ version.
Controller : Endpoint for sending messages to our Kafka server.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
@RestController @RequestMapping("/rest/api") public class KafkaController { @Autowired KafkaPublisher kafkaPublisher; @GetMapping(value = "/producer") public String sendMessage(@RequestParam("message") String message) { kafkaPublisher.sendMessage(message); return "Message sent Successfully to the your code decode topic "; } } |
KafkaTopicConfig : Configuration file used to create a topic with its name, partition and replication factor.
Note : We will learn more about the terms used here later in this part of the blog.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
@Configuration public class KafkaTopicConfig { @Value(value = "${spring.kafka.bootstrap-servers}") private String bootstrapAddress; @Bean public KafkaAdmin kafkaAdmin() { Map<String,Object> configs = new HashMap<>(); configs.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG,bootstrapAddress); return new KafkaAdmin(configs); } @Bean public NewTopic topic() { return new NewTopic("Topic1",1,(short)1); } } |
Publisher : Service that will publish messages that will be consumed by consumers.
Note : Consumer and publishers need not to be in same project. Here for simplicity of blog we have included consumer in same project but you can have different setup for consumer by providing right configuration’s in that setup.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
@Service public class KafkaPublisher { @Autowired KafkaTopicConfig kafkaTopicConfig; @Autowired private KafkaTemplate<String,String> kafkaTemplate; public void sendMessage(String msg) { ListenableFuture<SendResult<String,String>> future = kafkaTemplate. send( kafkaTopicConfig.topic().name(), msg ); future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() { @Override public void onFailure(Throwable ex) { System.out.println("Unable to send message ERROR : "+ex.getMessage()); } @Override public void onSuccess(SendResult<String, String> result) { System.out.println("Sent message=[" + msg + "] with offset=[" + result.getRecordMetadata().offset() + "]"); } }); } } |
Consumer : Service that will listen/consume the messages produced by producer.
Note : Consumer and publishers need not to be in same project. Here for simplicity of blog we have included consumer in same project but you can have different setup for consumer by providing right configuration’s in that setup.
|
1 2 3 4 5 6 7 8 9 10 |
@Service @Slf4j public class KafkaConsumer implements ConsumerSeekAware { @KafkaListener(id = "Consumer1" , topics = "Topic1",groupId = "1") public void listenGroupFoo(String mssg) { System.out.println("Message : "+mssg); } } |
ConsumerSeekAware : If we want to reset our offset and start reading messages from past we can do it using this. This will start seeking messages from start.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
@Component public class KafkaConsumerSeekAware extends AbstractConsumerSeekAware { Boolean reset = Boolean.TRUE; @KafkaListener(id = "Consumer2", topics = "Topic1", concurrency = "3" , groupId = "2") public void listen(String payload) { System.out.println("Listener received: " + payload); if(this.reset) { this.reset = Boolean.FALSE; seekToStart(); } } public void seekToStart() { getSeekCallbacks().forEach((tp, callback) -> callback.seekToBeginning(tp.topic(), tp.partition())); } } |
A snapshot of project running :
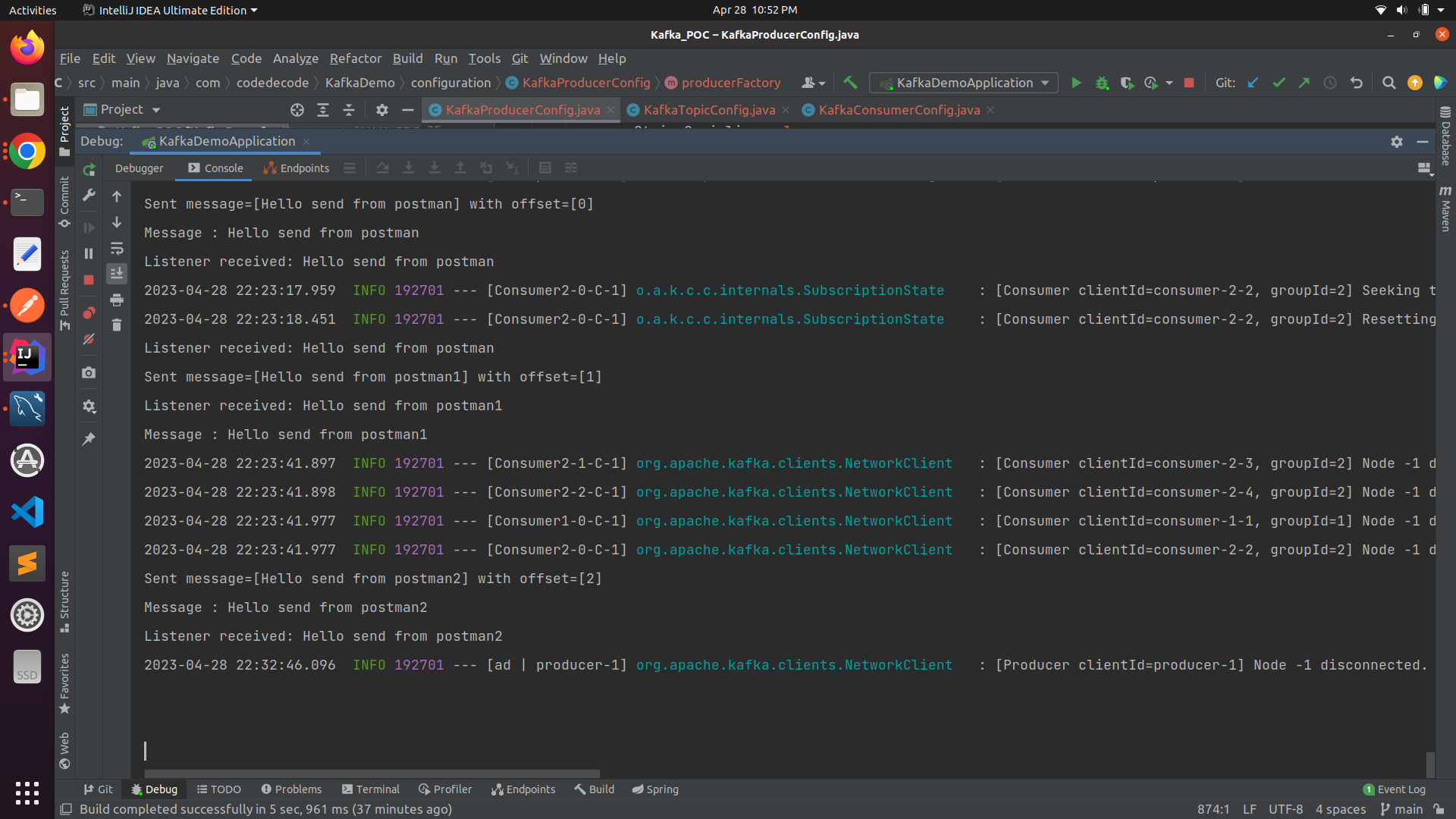
You can find the complete code for this project on the Git Repository :
https://github.com/akshat-jainn/Kafka_POC
Understanding commonly used terms :
- Producer : An application or system that produces data to Topics.
- Consumer : An application or system that consumes data from Topics.
- Consumer group : A group of consumers that collectively consume messages from one or more partitions of a topic. It assigns each consumer in the group to one or more partitions of the topic.
- Offset : A unique identifier that represents the position of a consumer within a partition of a topic. Kafka uses it to track consumption progress and ensure that each consumer in a group processes unique messages.
- Broker : A Kafka server that stores and manages the topic partitions and handles requests from producers and consumers.
- Leader : The broker responsible for handling all read and write requests for a particular partition of a topic.
- Follower : Kafka keeps a replica of a partition, which is not currently the leader but receives incremental updates to stay up-to-date with the leader’s data.
- Topic Name : Producers publish messages to a category or feed name called a topic, and consumers consume them. Kafka identifies topics by a string name that can contain any character allowed by the file system, except for the null character and the forward slash. Topics are the primary mechanism for message segregation, and multiple producers can publish messages to the same topic, and multiple consumers can subscribe to the same topic to receive the published messages.
- Partition : A partition is a unit of parallelism and scalability within a Kafka topic. Kafka can divide a topic into multiple partitions, and it can host each partition on a different broker in a Kafka cluster.
- ReplicationFactor : The replication factor in Kafka refers to the number of copies of a particular topic partition that Kafka maintains across different brokers in a Kafka cluster.
When to use Kafka and when to use RabbitMQ :
Both Kafka and RabbitMQ messaging systems find wide usage in distributed systems to enable communication between various components.While they both serve the same purpose, there are some significant differences between the two.
Kafka handles real-time data streams at scale and is designed as a streaming platform, while RabbitMQ is designed as a traditional message broker for messaging between applications.
- Architecture: Kafka is a distributed streaming platform, while RabbitMQ is a traditional message broker. Designers have developed Kafka to handle large volumes of data and stream processing, whereas they have designed RabbitMQ for message queuing.
- Latency: Kafka optimises for low latency and high throughput, making it an ideal choice for real-time processing of data, while RabbitMQ optimizes for reliability and message durability, which can result in slightly higher latency.
- Message delivery guarantees: Kafka guarantees at-least-once delivery, ensuring that messages are delivered at least once. On the other hand, RabbitMQ provides both at-most-once and at-least-once delivery guarantees, depending on the configuration.
- Protocols and APIs: Kafka supports a variety of protocols and APIs, including a native Java API, REST, and a command-line interface. RabbitMQ supports the Advanced Message Queuing Protocol (AMQP), which is a standard messaging protocol, as well as other protocols and APIs.
- Message ordering: Kafka is designed to maintain message order within a partition, but it does not maintain order across partitions. On the other hand, RabbitMQ preserves message order within a queue.
- Data processing: Streaming platforms optimize for processing continuous streams of data in real-time, whereas traditional message brokers optimize for queuing and message delivery.
- Scalability: Streaming platforms are highly scalable and can handle large volumes of data across multiple nodes and applications, while traditional message brokers are typically limited to a single node or cluster.
- Data persistence: Streaming platforms, such as Kafka, can persist data for longer periods of time and enable data replayability, while traditional message brokers are typically used for short-term storage and message delivery.
Hence we can conclude :
For use cases that require low latency and high throughput, Kafka is a better choice, whereas for use cases where reliability and message durability are critical, RabbitMQ is a better choice.
AMQP Protocol used by RabbitMQ:
Think of AMQP like a post office. Just like how you can send a letter or package to someone through a post office, you can use AMQP to send a message from one application to another. The AMQP protocol defines how to structure messages, deliver them, and ensure that the sender and receiver interact securely to guarantee reliable message delivery.
In technical words :
AMQP (Advanced Message Queuing Protocol) is a messaging protocol that allows different applications or systems to exchange messages in a reliable, secure, and efficient manner. AMQP provides a standard way for different applications to communicate with each other by sending and receiving messages.
Conclusion:
In this blog we discussed about what Kafka is, why we shifted from ZoopKeeper to KRaft, how to setup it in our system, how to implement a Spring Boot project using KRaft, brief about basic terminologies used, why and when to use Kafka over RabbitMQ, what is AMQP protocol.
Related content

Auriga: Leveling Up for Enterprise Growth!
Auriga’s journey began in 2010 crafting products for India’s