An Intelligent Knowledge Base with Generative AI
- Data, AI & Analytics

Project:
To develop a secure, cloud-based, and intelligent knowledge management system that provides users with instant, accurate answers from a vast repository of internal data.
The Challenge
In today’s fast-paced world, organizations are brimming with valuable knowledge, often trapped in a maze of documents, databases, and departmental silos. For a leading private organization, this meant decades of accumulated wisdom — from technical manuals to research papers — was scattered and hard to access. This led to:
- Wasted Time: Users spent countless hours sifting through information, hindering productivity.
- Isolated Data: Knowledge remained locked within departments, stifling collaboration.
- Inconsistent Information: Without a single source of truth, conflicting answers led to errors.
- Slow Onboarding: New hires struggled to get up to speed due to a lack of accessible information.
The need was clear: a centralized, intelligent system that could understand natural language and deliver precise, context-aware answers from their vast internal data.
The Solution A Retrieval-Augmented Generation (RAG) Engine
To address these critical challenges, we developed a bespoke, cloud-native Generative AI solution built on a Retrieval-Augmented Generation (RAG) architecture. This powerful system transforms static documents into a dynamic, searchable knowledge base.
Here’s how we did it:
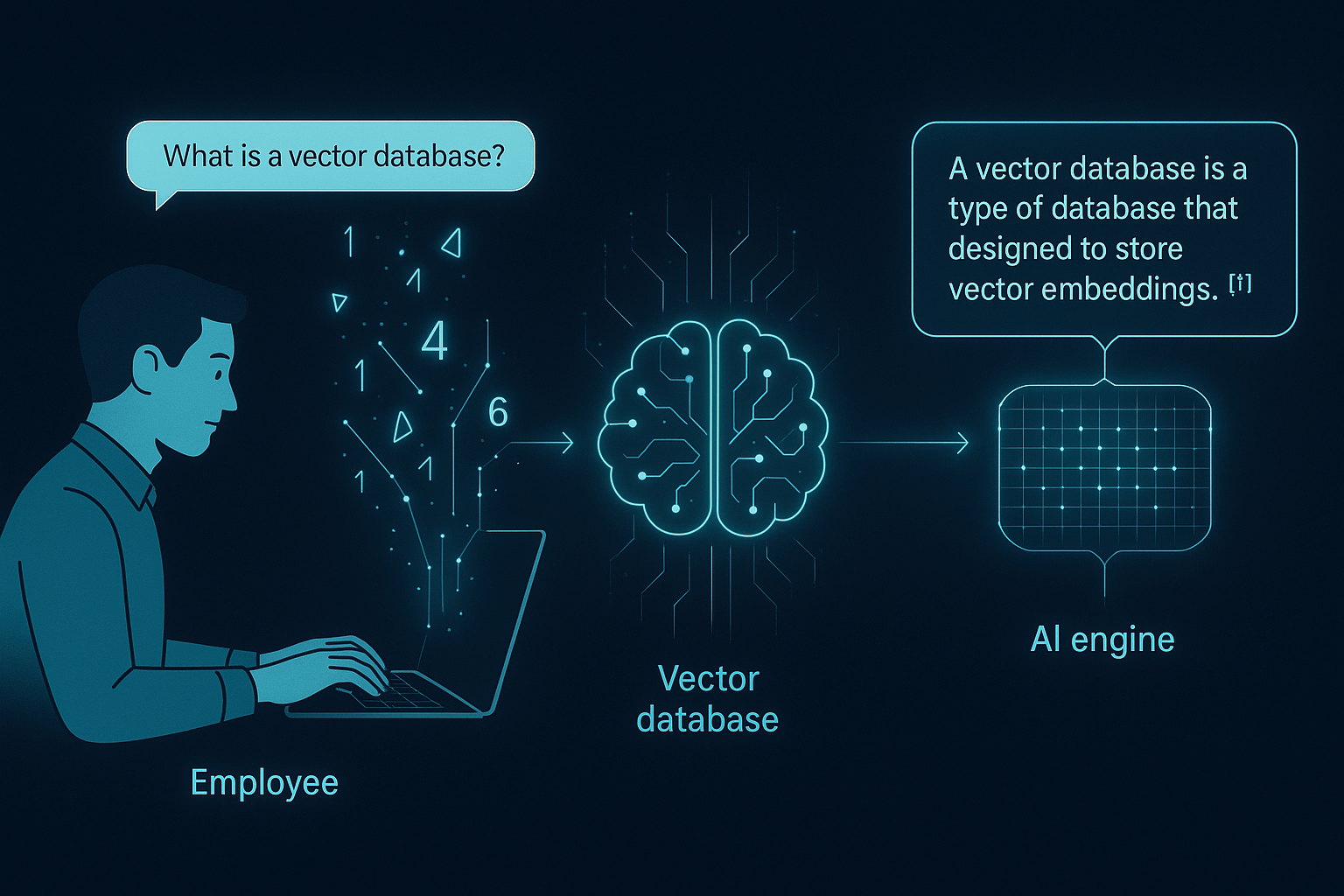
- Data Ingestion and Vectorization: We created a secure pipeline to ingest data from all the client’s internal sources. Each document was broken down into manageable “chunks.” Using a sophisticated embedding model, these text chunks were converted into numerical representations, or vectors, which capture their semantic meaning.

- Creating a Vector Database: These vectors were then stored and indexed in a specialized vector database. Optimized for high-speed similarity searches, this database allows the system to find the most relevant text chunks for any query almost instantly.
- The Question-Answering Engine: We built an intuitive user interface where employees can ask questions in plain English. When a query is submitted:
- The same embedding model converts the user’s question into a vector.
- The system searches the vector database to retrieve the most relevant document chunks based on vector similarity.
- These relevant chunks, along with the original question, are fed as context to a powerful Large Language Model (LLM).
- The LLM synthesizes the information from the retrieved chunks to generate a concise, accurate, and human-readable answer, complete with citations pointing to the source documents.
This entire solution was hosted on a secure cloud infrastructure, ensuring scalability, reliability, and data privacy.
“The core challenge wasn’t a lack of information, but a failure to access it effectively.”
Technical Architecture and Components
The success of this project hinged on a modern, robust technology stack:
- Cloud Platform: The entire solution was built on a leading cloud provider (e.g., AWS, Google Cloud, or Azure), leveraging its scalable compute, storage, and security services.
- Data Ingestion Pipeline: Custom scripts and managed ETL (Extract, Transform, Load) services were used to automate the process of collecting and preparing data from the client’s internal APIs and databases.
- Embedding Model: We utilized a state-of-the-art sentence-transformer model (e.g., from the Hugging Face library) to generate high-quality vector embeddings that accurately capture the nuances of the source text.
- Vector Database: A high-performance vector database (such as Pinecone, Weaviate, or ChromaDB) was deployed to handle the storage and rapid retrieval of millions of vector embeddings.
- Large Language Model (LLM): The core of our answering engine was powered by a secure deployment of a leading LLM (like OpenAI’s GPT-4 or Google’s Gemini). The model was accessed via its API and was not trained on the client’s data, ensuring complete data confidentiality.
- Orchestration Framework: The logic connecting the various components—from query embedding to context retrieval and final answer generation—was managed by an orchestration framework like LangChain, which streamlined development and ensured a modular architecture.
- Frontend and API: A secure REST API was exposed for the system’s backend. The user-facing application was a clean, responsive web interface built with a modern JavaScript framework, allowing for easy access from any device.
The Impact: Transforming Operations
The implementation of the GenAI knowledge base had a transformative impact on the organization: Drastic Reduction in Search Time: Employee time spent searching for information was reduced by over 90%.
- Increased Accuracy and Consistency: The system became the single source of truth, providing consistent and verifiable answers.
- Democratization of Knowledge: Silos were broken down as information from across the company became accessible to all authorized personnel.
- Empowered Workforce: Employees could self-serve information with confidence, leading to faster problem-solving, improved decision-making, and increased innovation.
This project successfully converted a static and fragmented data repository into a dynamic and intelligent asset, empowering the organization’s workforce and creating a significant competitive advantage.
Related Case Studies



SLA Financials