ONNX, ONNX Runtime, and TensortRT
- Data, AI & Analytics
ONNX, ONNX Runtime, and TensortRT
What is ONNX?
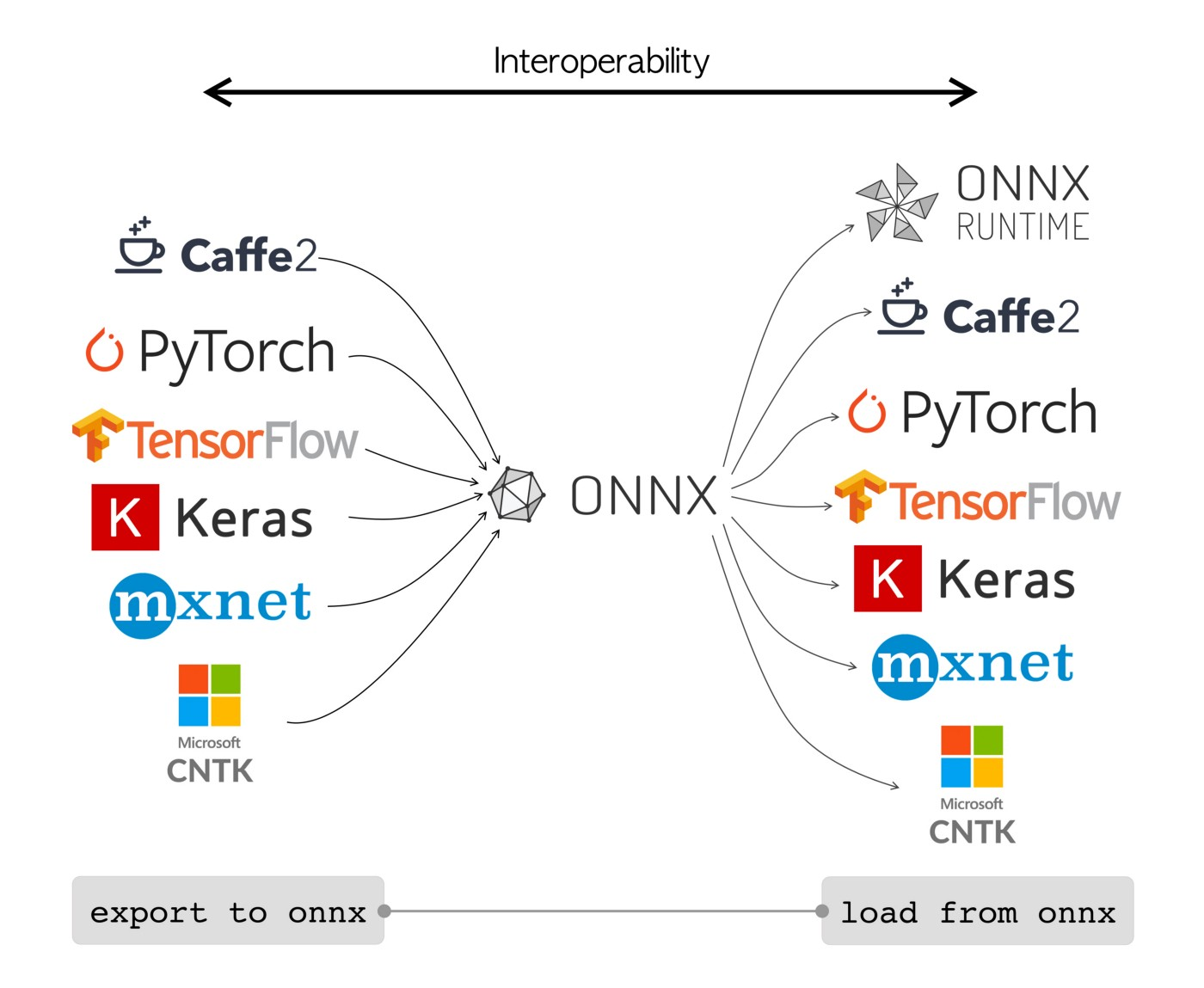
ONNX(Open Neural Network Exchange) defines a common set of operators – the building blocks of machine learning and deep learning models – and a common file format to enable AI developers to use models with a variety of frameworks, tools, runtimes, and compilers.
ONNX Design Principles
- Support DNN but also allows for traditional ML
- Flexible enough to keep up with rapid advances
- Compact and cross-platform representation
- Standardized list of well-defined operators informed by real-world usage
Export to ONNX
- Tensorflow to ONNX:
|
1 2 |
<span style="font-size: 1rem;"></span>!pip install git+https://github.com/onnx/tensorflow-onnx !python -m tf2onnx.convert --saved-model /content/model.tf --output tfmodel.onnx |
- Pytorch to ONNX:
|
1 2 3 |
from torch.autograd import Variable dummy_input = Variable(torch.randn(1,3,28,28)) torch.onnx.export(model_name, dummy_input, "model_pt.onxx") |
Load ONNX model
|
1 2 |
import onnx onnx_model = onnx.load('tfmodel.onnx') |
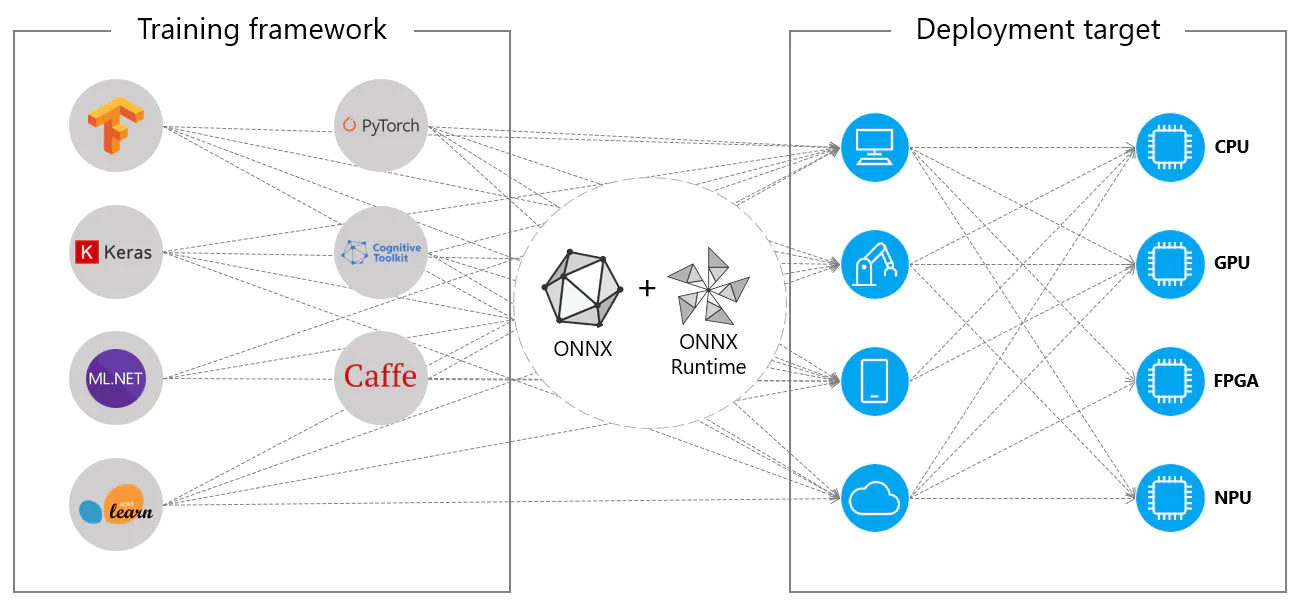
What is ONNX Runtime?
It is the High-Performance Inference engine for ONNX models founded and open-sourced by Microsoft under MIT License. It is designed to accelerate machine learning across a wide range of frameworks, operating systems, and hardware platforms.
While designing ONNX Runtime, they mainly focus on performance and scalability in order to support heavy workloads in high-scale production scenarios. So, it is supported on different Operating Systems and hardware platforms. The Execution Provider enables easy integration with Hardware accelerators.
Installation
|
1 |
!pip install onnxruntime |
Create Inference session to run onnx model in onnxruntime
|
1 2 |
import onnxruntime session_tf = onnxruntime.InferenceSession('model_path.onnx') |
Run the session
|
1 2 3 4 5 |
input_name = session_tf.get_inputs()[0].name output_name = session_tf.get_outputs()[0].name results_ort = session_tf.run( [output_name], {input_name: X.astype(np.float32)} ) |
ONNX Tool (Netron)
Netron is an open-source multi-platform visualizer of saved models. It supports many extensions for deep learning, machine learning, and neural network models.
NVIDIA TensorRT
It is an SDK for high-performance deep learning inference. It includes a deep learning inference optimizer and runtime that delivers low latency and high throughput for deep learning inference applications.
TensorRT based applications are 40 times faster than CPU-only based platforms during inference. With this, we can optimize performance Neural Network models trained in all major frameworks.
Features
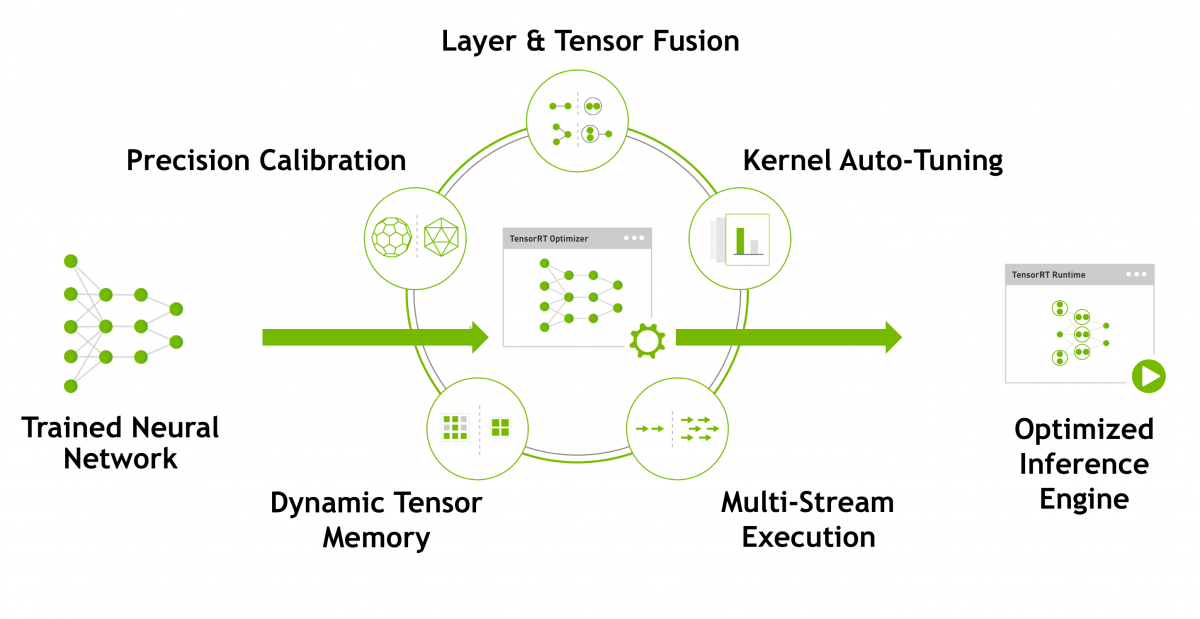
Precision Calibration
-
- Maximizes throughput with FP16 or INT8 by quantizing models while preserving accuracy
- Quantization is an optimization method in which model parameters and activations are converted from a floating-point to a lower-precision representation i.e., from FP32 to FP16 or INT8.
Layer & Tensor Fusion
-
- It Combines the several kernels so it executes at ones, so it is also called kernel fusion
- Kernel Fusion further classified into two types: Vertical Fusion and Horizontal Fusion
- In Vertical Fusion, layers with unused output are eliminated to avoid unnecessary computation
- In Horizontal layer fusion, layers that take the same source tensor and apply the same operations with similar parameters, result in a single larger layer for higher computational efficiency.
Kernel Auto-Tuning
-
- Selects best data layers and algorithms based on the target GPU platform
Multi-Stream Execution
-
- Process multiple inputs streams in parallel
Dynamic Tensor Memory
-
- Memory is allocated for each tensor and only for the duration of its usage.
TensorRT is also integrated with application-specific SDKs such as NVIDIA DeepStream, Riva, Merlin™, Maxine™, and Broadcast Engine to provide developers a unified path to deploy intelligent video analytics, conversational AI, recommender systems, video conference, and streaming apps in production.
Related content

Auriga: Leveling Up for Enterprise Growth!
Auriga’s journey began in 2010 crafting products for India’s