
- Data & Analytics
Snowflake vs Apache Druid: A Comparative Analysis for Modern Data Warehousing and Analytics
Snowflake vs Apache Druid: A Comparative Analysis for Modern Data Warehousing and Analytics
Snowflake and Apache Druid
Reporting Data Warehouses and Real-Time Analytics Databases have unique objectives and notable traits. Selecting the appropriate tool that aligns with your specific requirements is essential for accomplishing successful outcomes in your data projects.
Snowflake
A cloud-deployed Reporting Data Warehouse. Snowflake was founded in 2012 as a solution to the limitations of traditional data warehouses and complex Hadoop tools. It aimed to provide a scalable, cost-effective, and user-friendly platform for running reports in the cloud.
In Snowflake, data is stored in buckets using object storage, such as Amazon S3. This approach reduces costs significantly compared to high-speed storage options. However, it sacrifices speed for individual bucket operations. To compensate for this, Snowflake utilises massive parallelism by dividing data into micro-partitions as small as 50MB, each stored in its own bucket. Although the read and write speeds of each bucket may be slow, the overall parallel performance remains fast enough for practical usage, albeit slower than high-speed disk options.
Snowflake can also function as a data lake, where data is not ingested into micro-partitions but remains in files accessible for querying by Snowflake. This flexibility allows mixing data between files and micro-partitions, forming a concept known as a data lakehouse.
Snowflake is often chosen by organisations for generating reports on a regular basis, such as monthly, weekly, or daily reports. It provides a cost-effective data warehousing solution that meets the speed requirements for most reporting needs.
Apache Druid
A Real-Time Analytics Database. Druid was launched in 2011 to address the challenge of ingesting and querying billions of events within seconds. It is an open-source database and a project of the Apache Software Foundation, with over 1400 businesses and organisations relying on Druid for applications requiring speed, scalability, and streaming data.
In Druid, source data is ingested from various sources, including files and data streams like Apache Kafka and Amazon Kinesis. The data is processed, columnar, indexed, encoded, and compressed into immutable segments, distributed across multiple servers with copies stored in deep storage, typically an object store. Similar to Snowflake’s micro-partitions, these segments enable high performance while ensuring durability and availability.
Druid differs from reporting data warehouses in several key aspects:
- Sub-second Performance at Scale: Druid excels in providing interactive performance even with massive datasets, allowing users to quickly navigate and analyse complex information.
- High Concurrency: Druid supports high concurrency without requiring expensive infrastructure, making it suitable for scenarios with thousands of concurrent queries.
- Real-Time and Historical Data: Druid handles both real-time streaming data and batch data from various sources, enabling real-time understanding and meaningful historical comparisons.
- Continuous Availability: Druid is designed for uninterrupted operations, with continuous backups to prevent data loss. Planned downtime is unnecessary as scaling, upgrades, and other operations can be performed while the cluster remains operational.
Druid is ideal for interactive data exploration, where analysts and users need to drill down into data quickly, from a global perspective to detailed
For more about Apache Druid visit Apache Druid Introduction.
When to use Snowflake? When to use Druid?
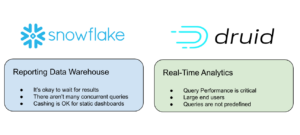
Snowflake is the better platform for regular reporting (daily, weekly, monthly, and such), especially where performance isn’t important – when you’re running a weekly report, it usually doesn’t matter if it takes a few seconds or an hour, as long as it works reliably
Druid is the better platform for interactive data exploration, where sub-second queries at scale enable analysts and others to quickly and easily drill through data, from the big picture down to any granularity. Druid is also the better platform for real-time analytics, when it’s important to have every incoming event in a data stream immediately available to query in context with historical data.
Conclusion
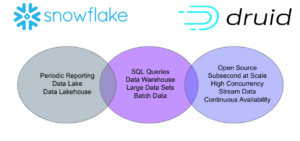
In summary, when it comes to choosing between Snowflake and Druid, it’s important to consider the specific requirements of your project. Snowflake is a suitable choice for generating regular reports and dashboards that are not heavily reliant on interactivity or real-time data. Its elasticity and cost-effectiveness make it a good fit for infrequent usage scenarios.
On the other hand, Druid excels when it comes to interactive data exploration, providing sub second response times even with large datasets. It is particularly well-suited for applications that require high concurrency, real-time analytics, and continuous availability. If your project demands these capabilities, Druid would be the preferred option.
It’s worth noting that there are use cases where both Snowflake and Druid can be viable solutions. For tasks such as operational visibility, security and fraud analytics, and understanding user behaviour, Snowflake may suffice if performance, concurrency, and up time are not critical factors. However, if sub second response times, high concurrency, or continuous availability are essential, Druid would be the better choice.
Ultimately, the decision between Snowflake and Druid depends on your specific needs and priorities. It’s not about replacing one with the other but rather selecting the right tool for the job at hand.
Related content

Auriga: Leveling Up for Enterprise Growth!
Auriga’s journey began in 2010 crafting products for India’s [...]




