
- General
Spring Batch : CSV to Database
Spring Batch : CSV to Database
Introduction To Spring Batch
Spring Batch provides reusable functions that are essential in processing large volumes of records, including logging/tracing, transaction management, job processing statistics, job restart, skip, and resource management. It also provides more advanced technical services and features that will enable extremely high-volume and high performance batch jobs through optimization and partitioning techniques. Simple as well as complex, high-volume batch jobs can leverage the framework in a highly scalable manner to process significant volumes of information.
Features
- Transaction management
- Chunk based processing
- Declarative I/O
- Start/Stop/Restart
- Retry/Skip
- Web based administration interface
Use-Case
In this article, we’ll go through how to create a Spring Batch Job from start to end for inserting high-volume data from CSV into a database with the help of Batch Core components which otherwise is a tedious process to do i.e. create a statement and execute the query.
Apart from the previously used strategies, Spring Batch provides us with an Admin Dashboard to monitor jobs, outcomes, and logs. And with @Transactional Annotation, we can roll back the entire transaction steps if an error occurred.
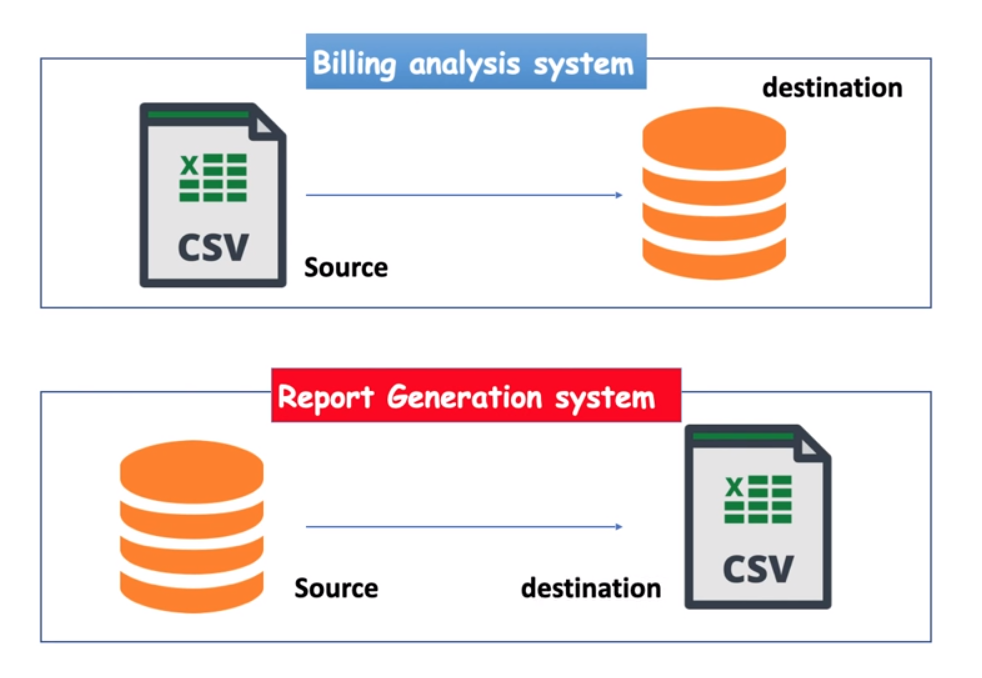
Spring Batch Core Components And Flow
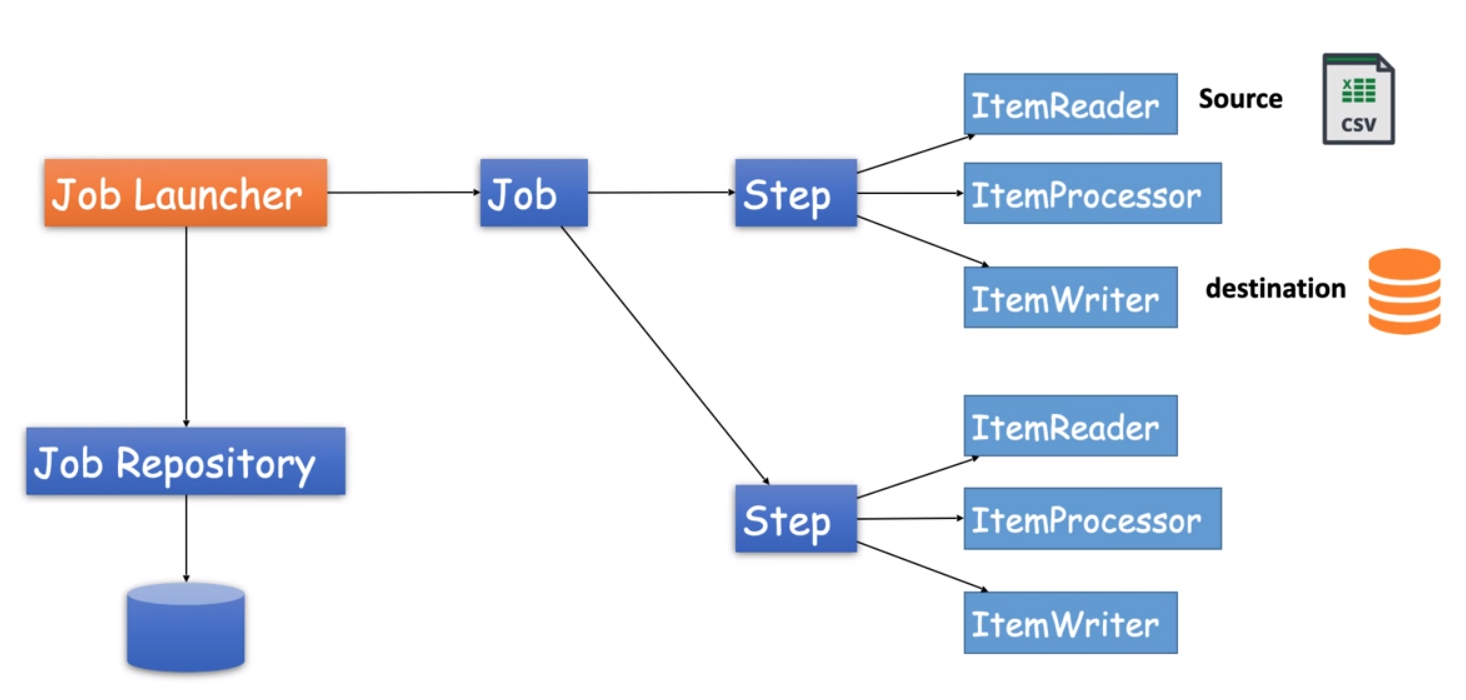
Creating a Spring Batch Project
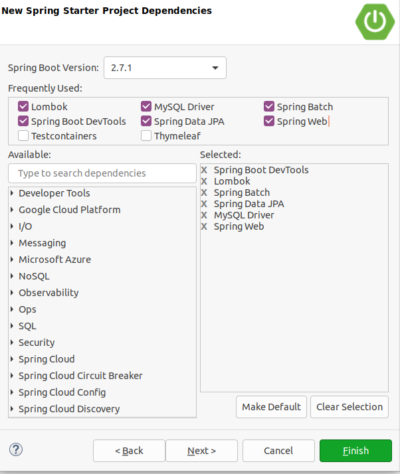
Spring Project Configuration
|
1 2 3 4 5 6 7 8 9 10 11 12 |
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.url = jdbc:mysql://localhost:3306/DB_Name spring.datasource.username = username spring.datasource.password = password #spring.jpa.show-sql = true spring.jpa.hibernate.ddl-auto = update spring.jpa.properties.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect #server.port=9191 spring.batch.initialize-schema=ALWAYS #disabled job run at startup spring.batch.job.enabled=false |
Creating entity for our CSV File
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
@Entity @Table(name = "CUSTOMERS_INFO") @Data @AllArgsConstructor @NoArgsConstructor public class Customer { @Id @Column(name = "CUSTOMER_ID") private int id; @Column(name = "FIRST_NAME") private String firstName; @Column(name = "LAST_NAME") private String lastName; @Column(name = "EMAIL") private String email; @Column(name = "GENDER") private String gender; @Column(name = "CONTACT") private String contactNo; @Column(name = "COUNTRY") private String country; @Column(name = "DOB") private String dob; } |
Configuration For Job, Step, ItemReader, ItemWriter, ItemProcessor
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
@Configuration @EnableBatchProcessing @AllArgsConstructor public class SpringBatchConfig { private JobBuilderFactory jobBuilderFactory; private StepBuilderFactory stepBuilderFactory; private CustomerRepository customerRepository; @Bean public FlatFileItemReader<Customer> reader() { FlatFileItemReader<Customer> itemReader = new FlatFileItemReader<>(); itemReader.setResource(new FileSystemResource("src/main/resources/customers.csv")); itemReader.setName("csvReader"); itemReader.setLinesToSkip(1); itemReader.setLineMapper(lineMapper()); return itemReader; } private LineMapper<Customer> lineMapper() { DefaultLineMapper<Customer> lineMapper = new DefaultLineMapper<>(); DelimitedLineTokenizer lineTokenizer = new DelimitedLineTokenizer(); lineTokenizer.setDelimiter(","); lineTokenizer.setStrict(false); lineTokenizer.setNames("id", "firstName", "lastName", "email", "gender", "contactNo", "country", "dob"); BeanWrapperFieldSetMapper<Customer> fieldSetMapper = new BeanWrapperFieldSetMapper<>(); fieldSetMapper.setTargetType(Customer.class); lineMapper.setLineTokenizer(lineTokenizer); lineMapper.setFieldSetMapper(fieldSetMapper); return lineMapper; } @Bean public CustomerProcessor processor() { return new CustomerProcessor(); } @Bean public RepositoryItemWriter<Customer> writer() { RepositoryItemWriter<Customer> writer = new RepositoryItemWriter<>(); writer.setRepository(customerRepository); writer.setMethodName("save"); return writer; } @Bean public Step step1() { return stepBuilderFactory.get("csv-step").<Customer, Customer>chunk(10) .reader(reader()) .processor(processor()) .writer(writer()) .taskExecutor(taskExecutor()) .build(); } @Bean public Job runJob() { return jobBuilderFactory.get("importCustomers") .flow(step1()).end().build(); } @Bean public TaskExecutor taskExecutor() { SimpleAsyncTaskExecutor asyncTaskExecutor = new SimpleAsyncTaskExecutor(); asyncTaskExecutor.setConcurrencyLimit(10); return asyncTaskExecutor; } } |
Custom Item Processor
|
1 2 3 4 5 6 7 8 9 10 11 |
public class CustomerProcessor implements ItemProcessor<Customer,Customer> { @Override public Customer process(Customer customer) throws Exception { if(customer.getCountry().equals("United States")) { return customer; }else{ return null; } } } |
Customer Repository
|
1 2 3 |
public interface CustomerRepository extends JpaRepository<Customer,Integer> { } |
Job Controller
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
@RestController @RequestMapping("/jobs") public class JobController { @Autowired private JobLauncher jobLauncher; @Autowired private Job job; @PostMapping("/importCustomers") public void importCsvToDBJob() { JobParameters jobParameters = new JobParametersBuilder() .addLong("startAt", System.currentTimeMillis()).toJobParameters(); try { jobLauncher.run(job, jobParameters); } catch (JobExecutionAlreadyRunningException | JobRestartException | JobInstanceAlreadyCompleteException | JobParametersInvalidException e) { e.printStackTrace(); } } } |
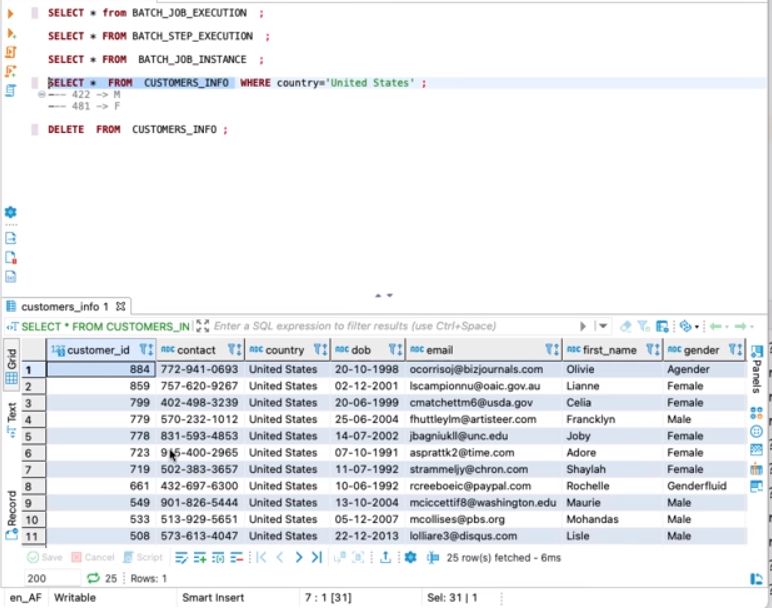
Batch Job Output in DB
Related content

Auriga: Leveling Up for Enterprise Growth!
Auriga’s journey began in 2010 crafting products for India’s [...]
Stay Close to What We’re Building
Get insights on product engineering, AI, and real-world technology decisions shaping modern businesses.



