Supercharging Live Alerts With Redis And Kafka
Supercharging Live Alerts With Redis And Kafka
Supercharging Live Alerts With Redis And Kafka
Optimizing Live Alerts with Kafka and Redis
Introduction
Real-time systems demand both speed and reliability, especially when dealing with high-frequency sensor data. This was the challenge faced while implementing live alerts . Initially, the system relied on a database-centric approach, where data was stored, and a cron job executed every 5 minutes to evaluate alert conditions. However, this caused significant delays, as the increasing volume of IOT data made the process sluggish and unscalable. To address these issues, we revamped the system with Kafka and Redis, achieving near-instantaneous processing and alerting capabilities.
Challenges with the Initial Setup
- Delayed Alerts: Cron jobs executed every 5 minutes introduced inherent delays, making the system incapable of real-time alerts.
- High Database Load: With rows of sensor data continuously flooding the database, querying and processing became a bottleneck.
- Scalability Issues: As the data volume grew, the time to process alerts increased proportionally, leading to performance degradation.
Transitioning to Kafka and Redis
To overcome these bottlenecks, the system was re-engineered with a focus on real-time data streaming and processing. Kafka was introduced to handle high-throughput, distributed message streaming, and Redis was chosen for its speed and versatility in maintaining a replica-like data store.
- Kafka for Message Streaming:
-
- Sensor data was streamed in real-time to Kafka topics, ensuring a continuous flow of data without delays.
- Kafka’s partitioning and fault tolerance allowed the system to scale efficiently.
- Redis as a Real-Time Data Store:
-
- Redis was utilized to create a database-like replica of sensor data.
- Redis Pub/Sub ensured that any changes or updates made by users were instantly published and synced.
- Redis Streams enabled efficient handling of event queues for processing and alerting.
Implementing Redis for Real-Time Processing
The core of the revamped system was Redis, extensively used to solve several key challenges:
- Database-Like Replica
-
- Due to certain changes made by users , it was important to maintain almost similar database-like structure in redis using HASH SETS . Using a pub/ sub system the changes were captured instantaneously and changes were reflected and then stored permanently onto redis .
- HSETs with similar prefixes were queried dynamically to retrieve relevant sensor data using Rejson . It ensured efficient reads for multiple data points
- Pub/Sub for Data Updates :
-
- A publish/subscribe mechanism ensured that any update or change made by users was immediately reflected in Redis.
- These updates were captured and permanently stored in the database through a dedicated listener service.
- Condition Evaluation for Alerts:
- Kafka messages were polled live to check predefined alert conditions.
- If conditions were met, alert notifications were pushed to Redis Streams for email processing.
Walk Through Of The Process
1) Enabling redis-stack server
- First we would need a redis-stack server to add on redis features .
|
1 2 3 4 5 6 7 8 9 |
sudo apt-get install lsb-release curl gpg curl -fsSL https://packages.redis.io/gpg | sudo gpg --dearmor -o /usr/share/keyrings/redis-archive-keyring.gpg sudo chmod 644 /usr/share/keyrings/redis-archive-keyring.gpg echo "deb [signed-by=/usr/share/keyrings/redis-archive-keyring.gpg] https://packages.redis.io/deb $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/redis.list sudo apt-get update sudo apt-get install redis-stack-server sudo systemctl enable redis-stack-server sudo systemctl start redis-stack-server |
- In order to check if redis-stack server is actually installed in terminal follow the below process
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
redis-cli MODULE LIST Upon successful installation , you would see something like this . 1) 1) "name" 2) "search" 3) "ver" 4) (integer) 21005 5) "path" 6) "/opt/redis-stack/lib/redisearch.so" 7) "args" 8) 1) "MAXSEARCHRESULTS" 2) "10000" 3) "MAXAGGREGATERESULTS" 4) "10000" 2) 1) "name" 2) "RedisCompat" ………… |
2) Django signals to publish changes to redis
- Django Side Snapshot
|
||
- A service would be subscribed and continuously listen to messages . The service then would permanently store the messages onto a hash key .
|
- The messages are stored into a hash keys that have common prefix . This is maintained as redis queries only work on hash keys with common prefix . Attaching redis snapshot ..
- Kafka consumers are setup and messages are consumed . An example on how to setup redis index and effectively query on it is shown below .
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
Redis cli command . FT.CREATE alert_index ON HASH PREFIX 1 "/digin/comp/alert/details/" SCHEMA alert_type TEXT FT.SEARCH /digin/comp/alert/details/ "@alert_type:1" IN Python """ columns = [ ("sensor_id", FieldType.TEXT), ("details", FieldType.TEXT), ("price", FieldType.NUMERIC), ("location", FieldType.GEO), ("tags", FieldType.TAG) ] """ def _create_index(self ,index_name = None , definition = None , fields = None): try: self.r.ft(index_name).create_index(fields=fields, definition=definition) except: logger.info("index already exists") def create_index(self ,index_name = None, doc_prefix = None , index_type = IndexType.HASH , columns = [] , drop_idx = False): definition = IndexDefinition(prefix=[doc_prefix], index_type=IndexType.HASH) # “ schema_fields.append(TextField(column_name , no_stem=True)) ” self._create_index(index_name = index_name , fields = schema_field_list , definition = definition) .......... ……………. Redis_operations.create_index(*args , **kwargs) |
An index is created with the name we choose ( typical copy of a database index );
- A snapshot on how to query index :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
An index of type text on alert type is created on prefix /digin/comp/alert/details/* search_query = Query(f"@alert_type:{alert_type_id}") index_name = "alert_alert_type_idx" results = self.r.ft(index_name).search(query = query) final_data = [] for doc in results.docs: tmp = doc.__dict__ final_data.append(tmp) return final_data |
- When alert is raised , alert entry is done in notification and database stream . Example are as follows .
|
Architectural Diagram
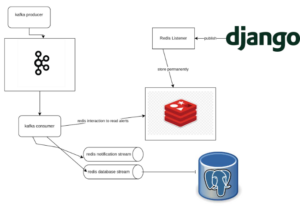
System Architecture
Conclusion
By shifting from a database-cron system to a Kafka-Redis architecture, the live alert system achieved real-time processing, scalability, and reliability. Leveraging Redis JSON for querying, Pub/Sub for updates, and Streams for notifications proved to be pivotal in the system’s success. This solution not only addressed the immediate performance issues but also laid a robust foundation for future scalability and enhancements.
Resources
- Redis Docs : Docs
- Download Redis insights : Redis Insight
- Redis Streams : Redis Streams Featuring Salvatore Sanfilippo – Redis Labs
Related content

Auriga: Leveling Up for Enterprise Growth!
Auriga’s journey began in 2010 crafting products for India’s