Understanding RAG: Retrieval-Augmented Generation for Smarter AI
Understanding RAG: Retrieval-Augmented Generation for Smarter AI
In the era of generative AI, Large Language Models (LLMs) like GPT-4, Claude, and Gemini are transforming the way we interact with technology. But even these powerful models have limitations—especially when it comes to real-time accuracy. This is where Retrieval-Augmented Generation (RAG) comes in.
This blog will walk you through the fundamentals of RAG, how it works, and why it’s a game-changer in AI applications.
What is an LLM?
Large Language Models (LLMs) are a class of advanced AI models that specialize in understanding and generating human-like text. They belong to the field of deep learning, a subset of machine learning, and are trained on massive datasets that include books, articles, websites, and other textual resources from the internet.
LLMs are built on a foundational neural network design called the Transformer architecture, first introduced by Google in the landmark 2017 paper “Attention is All You Need.” This architecture revolutionized natural language processing (NLP) by introducing a mechanism called self-attention, which allows models to weigh the importance of different words in a sentence relative to one another—regardless of their position.
Thanks to this architecture, LLMs can:
- ✅ Understand context across long documents
- ✅ Generate coherent and fluent text
- ✅ Translate languages with high accuracy
- ✅ Summarize large texts into concise overviews
- ✅ Answer questions, write code, and even reason through logic
In essence, LLMs don’t just memorize data—they learn to generalize language patterns, enabling them to predict and generate relevant responses based on the prompts they receive.
Some of the most well-known LLMs today include:
- 🧠 GPT-4 (successor to GPT-3 and GPT-3.5)
- 🔍 LLaMA (by Meta)
- ✍️ Claude (by Anthropic)
- 🛠️ PaLM and Gemini (by Google DeepMind)
Key Concepts in LLMs (Large Language Models)
To fully grasp how LLMs work, it’s essential to understand a few fundamental terms that define their architecture and behavior:
1. Parameters
Parameters are the internal “knobs” that a model learns during training. They represent the weights that define how input data transforms into output. The more parameters a model has, the more complex patterns it can learn.
-
Example: GPT-3 has 175 billion parameters, enabling it to understand and generate highly nuanced text.
-
Think of parameters as the model’s long-term memory—they encode everything it has learned during training.
2. Context Length (Context Window)
This refers to the maximum number of tokens an LLM can consider at once during input and output generation.
-
For instance, GPT-3.5 has a context length of 4,096 tokens, while GPT-4 can support up to 32,768 tokens (and even 128k in some variants).
-
Why it matters: If your input exceeds this limit, the earliest parts of the input may be dropped, potentially affecting response accuracy.
3. Tokens
Tokens are the basic units of text processed by LLMs. A token might be a word, part of a word, or even punctuation, depending on the tokenizer.
-
Examples:
-
“ChatGPT is cool!” → might be tokenized as
["Chat", "G", "PT", " is", " cool", "!"]
-
-
Most models use Byte Pair Encoding (BPE) or similar algorithms to tokenize efficiently.
4. Prompt
A prompt is the input text you provide to the model. It guides the model’s response.
-
Prompts can be simple: “Translate this to French: Hello.”
-
Or complex: “Given the following financial data, summarize quarterly performance and highlight anomalies.”
-
Crafting effective prompts—known as prompt engineering—is key to getting high-quality outputs.
5. Temperature
This hyperparameter controls the randomness and creativity of the model’s response.
-
Range: Typically from 0.0 to 1.0 (or even higher)
-
Low temperature (e.g., 0.2): Output is more focused, deterministic, and factual.
-
High temperature (e.g., 0.8): Responses become more diverse, creative, and open-ended.
-
-
Use lower values for tasks requiring precision (like coding or factual Q&A) and higher values for brainstorming or
The Limitations of LLMs – Why RAG Is Needed
While Large Language Models (LLMs) are incredibly advanced, they aren’t flawless. In real-world applications, their limitations can have significant consequences, especially when accuracy, timeliness, and context are critical. Let’s explore the key challenges:
1. Hallucination
LLMs can “hallucinate”, meaning they sometimes generate outputs that sound plausible but are factually incorrect or entirely made up.
-
Example: An LLM might fabricate a research paper reference or invent a quote from a public figure.
-
Why it happens: The model generates text based on patterns it has seen in its training data—not on real-time facts or external validation.
2. Stale Knowledge
Most LLMs are trained on a fixed dataset that only includes information available up to a certain point in time.
-
For example, GPT-3.5’s knowledge cutoff is 2021, and while GPT-4 can be updated, it still doesn’t have true live access to the internet unless specifically integrated.
-
Result: LLMs may not know about recent events, new technologies, or updated regulations—limiting their usefulness in time-sensitive scenarios.
3. Limited Context Window
LLMs process input using a context window, which defines how much information the model can “see” at once.
-
If a document exceeds this limit (e.g., over 4,000 or 32,000 tokens), the model cannot consider the full document while generating a response.
-
This makes it difficult to work with long documents, such as legal contracts, research papers, or large knowledge bases, without losing context.
Enter RAG — Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) is a powerful architectural enhancement that solves these issues by combining the strengths of LLMs with real-time, context-aware data retrieval.
How RAG Helps:
Instead of relying solely on what the model remembers from training, RAG retrieves relevant information from external sources (like databases, PDFs, or websites) just before generating a response.
Key advantages:
- ✅ Reduces hallucination by grounding answers in real data.
- ✅ Provides up-to-date information without retraining the model.
- ✅ Expands effective context by allowing the model to access relevant chunks dynamically.
What is RAG and How Does It Work?
RAG is a hybrid approach that significantly enhances the performance of Large Language Models (LLMs) by combining retrieval-based and generation-based methods. It empowers models like GPT, LLaMA, and Claude to provide factually accurate, context-aware responses—even when the base model doesn’t have the required information in its training data.
The Core Idea
Traditional LLMs generate answers solely based on their pretrained knowledge, which:
-
Is fixed at the time of training
-
May not include the latest information
-
Can lead to hallucinations (i.e., making up facts)
RAG solves this problem by enabling the model to first retrieve relevant external data and then generate an answer based on that data.
RAG = Retrieval + Generation
1. Retriever
-
This component searches a large corpus (e.g., PDFs, databases, websites) to find the most relevant information based on the user’s query.
-
Instead of keyword search, RAG uses vector similarity search:
-
Converts both the query and documents into embeddings (dense vector representations)
-
Compares vectors to retrieve the most semantically relevant chunks
-
-
These documents act as external memory to support the model.
Example Tools: FAISS, ChromaDB, Pinecone, Weaviate
2. Generator
-
Once the retriever provides context (typically 3–5 top matching chunks), the LLM is prompted with both the user’s question and the retrieved content.
-
The LLM then generates a response grounded in the actual, retrieved knowledge—making it more reliable and verifiable.
-
This step uses prompt engineering techniques to maximize relevance and reduce hallucination.
Example Models: GPT-4, LLaMA, Claude, Mistral
Core Components of a RAG Pipeline
-
Chunking: Breaking large documents into manageable pieces.
-
Embeddings: Converting text chunks into numerical vectors.
-
Vector Databases (e.g., Chroma DB): Store embeddings and allow fast similarity searches.
-
Frameworks (e.g., LangChain): Manage the RAG workflow efficiently.
RAG Architecture: How It All Comes Together
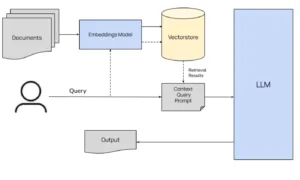
1. Document Ingestion
-
A collection of unstructured documents (PDFs, articles, manuals, etc.) is prepared as the knowledge base.
-
Each document is chunked into smaller segments (e.g., paragraphs or sections) for better granularity.
2. Embeddings Generation
-
Each document chunk is passed through an Embeddings Model (e.g., OpenAI, HuggingFace Transformers) that converts text into a vector (numeric representation).
-
These vectors capture semantic meaning, not just keyword similarity.
3. Vectorstore Indexing
-
The embeddings are stored in a Vectorstore (e.g., FAISS, ChromaDB, Pinecone).
-
The vector database supports fast nearest-neighbor search, enabling efficient retrieval of relevant content.
4. User Query
-
The user submits a natural language query.
-
This query is also converted into an embedding using the same embedding model.
5. Document Retrieval
-
The query embedding is matched against the vectorstore.
-
The top-N most similar document chunks are retrieved (based on cosine similarity or another metric).
6. Prompt Construction
-
The retrieved content is combined with the original user query into a structured prompt (also known as context-enhanced input).
-
Example: “Here are some documents: […]. Based on these, answer: [query]”
7. LLM Generation
-
The prompt is passed to the Large Language Model (LLM) (e.g., GPT-4, LLaMA, Claude).
-
The LLM uses this contextual information to generate a fact-grounded, accurate response.
8. Response Output
-
The model’s output is delivered to the user.
-
Optionally, the system can also return the source documents used for the response to enhance transparency.
Real-World Use Cases
1. Customer Support Chatbots
-
Problem: Traditional chatbots are limited to pre-programmed responses or outdated FAQs.
-
With RAG:
-
The bot can retrieve the most relevant product documentation, troubleshooting guides, or user manuals in real time.
-
It enables personalized, accurate answers—even for complex or rare customer issues.
-
-
Example: An ISP chatbot retrieves router setup instructions from PDF manuals and responds in natural language.
2. Legal Document Search and Summarization
-
Problem: Legal professionals spend hours scanning lengthy case files, contracts, and regulations.
-
With RAG:
-
A legal assistant tool retrieves relevant case law, clauses, or precedents and summarizes them on demand.
-
It can answer questions like “What precedent supports breach of contract under X condition?”
-
-
Example: A lawyer uploads case files and queries “Find all arbitration clauses.” The RAG system retrieves and highlights exact locations from hundreds of pages.
3. Medical and Scientific Research Assistants
-
Problem: Researchers must comb through vast volumes of journals, studies, and clinical data.
-
With RAG:
-
The system retrieves the latest studies or data on a medical condition or treatment.
-
Answers are generated with citations from PubMed, journals, or internal databases.
-
-
Example: A doctor asks, “What are the recent findings on CRISPR in cancer therapy?” The assistant summarizes papers from the past 6 months.
4. Internal Knowledge Base Q&A (Enterprise Search)
-
Problem: Employees waste time looking for policies, HR procedures, or engineering docs.
-
With RAG:
-
An internal assistant can pull answers from wikis, Google Drive, Confluence, or SharePoint.
-
Ensures that employees always get accurate, policy-aligned responses.
-
-
Example: An employee types, “How many vacation days do I get after 3 years?” and gets an answer from the most recent HR policy document.
Types of RAG
1. Corrective RAG — “Fact-Check-as-You-Generate”
-
What it does: Continuously monitors the generated output for hallucinations (fabricated or incorrect facts) and uses retrieval to verify or correct them in real-time.
-
How it works:
-
During or after generation, the system re-queries the vector database to validate factual claims.
-
If a mismatch is found between the generated text and the actual source, the answer is flagged or corrected.
-
-
Use case: Medical assistants, legal advisors, or academic tools where factual accuracy is critical.
✅ Example: A model suggests a legal clause. Corrective RAG cross-checks it with the latest legal code and corrects any outdated references.
2. Speculative RAG — “Try Multiple Answers, Choose the Best”
-
What it does: Generates multiple potential answers based on various retrieval contexts, then uses a scoring function to pick the most accurate or relevant one.
-
How it works:
-
Retrieves different sets of documents
-
Generates multiple candidate answers
-
Ranks them based on criteria like semantic similarity, confidence, or user intent match
-
-
Use case: Open-ended question answering, brainstorming, research tools
✅ Example: A scientific assistant presents multiple hypotheses and chooses the one most aligned with current research.
3. Fusion RAG — “Merge Knowledge from Many Sources”
-
What it does: Retrieves from multiple data sources or retrievers and fuses the results into a unified context for the LLM to generate a richer, more complete answer.
-
How it works:
-
Fetches top chunks from various vectorstores (e.g., product docs, customer chats, FAQs)
-
Merges or filters the results before prompting the LLM
-
-
Use case: Multi-source customer support, cross-department enterprise Q&A
✅ Example: A system answering a product question retrieves from both product manuals and support tickets to deliver a well-rounded answer.
4. Agentic RAG — “RAG + Autonomous Reasoning Agents”
-
What it does: Embeds RAG inside a multi-step reasoning agent that plans actions, retrieves data as needed, and executes tasks autonomously.
-
How it works:
-
A reasoning engine (like a ReAct or LangGraph agent) breaks a task into steps
-
At each step, it uses RAG to retrieve specific knowledge
-
It decides what to do next based on the updated context
-
-
Use case: Complex workflows like legal analysis, travel planning, data analysis
✅ Example: An AI legal assistant that reads a case, looks up statutes, asks follow-up questions, and generates a legal brief—step by step.
✅ Conclusion
Retrieval-Augmented Generation elevates the capabilities of LLMs by giving them access to up-to-date, accurate, and domain-specific information—transforming them into supercharged problem-solvers.
Whether you’re building a chatbot, search assistant, or enterprise AI application, RAG is your go-to technique for accuracy, trustworthiness, and context-awareness.
Related content

Auriga: Leveling Up for Enterprise Growth!
Auriga’s journey began in 2010 crafting products for India’s