Apache Druid: Exploring Its Capabilities
- General
- Data, AI & Analytics

Apache Druid: Exploring Its Capabilities
In today’s world of big data, businesses are constantly seeking ways to harness insights from vast amounts of data in real time. Traditional databases often struggle to meet the demands of modern applications requiring sub-second query responses over large datasets. Enter Apache Druid—an open-source, real-time analytics database designed to address these challenges. In this blog, we’ll explore what makes Apache Druid unique, its architecture, use cases, and why it’s a go-to choice for real-time data analytics.
What is Apache Druid?
Apache Druid is a high-performance, column-oriented, distributed data store primarily designed for real-time analytics on time-series data. It combines features from data warehouses, time-series databases, and search systems, enabling it to handle large datasets with speed and efficiency. Druid is ideal for applications where fast, interactive queries are essential, such as dashboards, reports, and data visualizations.
Key Features of Apache Druid
Druid’s core architecture combines ideas from data warehouses, timeseries databases, and logsearch systems. Some of Druid’s key features are:
- Columnar storage format: Druid uses column-oriented storage. This means it only loads the exact columns needed for a particular query. This greatly improves speed for queries that retrieve only a few columns. Additionally, to support fast scans and aggregations, Druid optimizes column storage for each column according to its data type.
- Scalable distributed system: Typical Druid deployments span clusters ranging from tens to hundreds of servers. Druid can ingest data at the rate of millions of records per second while retaining trillions of records and maintaining query latencies ranging from the sub-second to a few seconds.
- Massively parallel processing: Druid can process each query in parallel across the entire cluster.
- Realtime or batch ingestion: Druid can ingest data either real-time or in batches. Ingested data is immediately available for querying.
- Cloud-native, fault-tolerant architecture that won’t lose data: After ingestion, Druid safely stores a copy of your data in deep storage. Deep storage is typically cloud storage, HDFS, or a shared filesystem. You can recover your data from deep storage even in the unlikely case that all Druid servers fail. For a limited failure that affects only a few Druid servers, replication ensures that queries are still possible during system recoveries.
- Indexes for quick filtering: Druid uses Roaring or CONCISE compressed bitmap indexes to create indexes to enable fast filtering and searching across multiple columns.
- Time-based partitioning: Druid first partitions data by time. You can optionally implement additional partitioning based upon other fields. Time-based queries only access the partitions that match the time range of the query which leads to significant performance improvements.
- Approximate algorithms: Druid includes algorithms for approximate count-distinct, approximate ranking, and computation of approximate histograms and quantiles. These algorithms offer bounded memory usage and are often substantially faster than exact computations. For situations where accuracy is more important than speed, Druid also offers exact count-distinct and exact ranking.
- Automatic summarization at ingest time: Druid optionally supports data summarization at ingestion time. This summarization partially pre-aggregates your data, potentially leading to significant cost savings and performance boosts.
Why Choose Apache Druid?
Druid stands out because it combines the speed of real-time analytics systems with the scalability and flexibility of big data technologies. Here’s why you should consider Druid for your analytics needs:
- Fast Query Performance: Druid is built for speed, providing sub-second query results even with massive datasets.
- Real-Time Insights: Unlike many databases that are limited to either real-time or batch processing, Druid handles both seamlessly.
- Cost Efficiency: Druid’s use of data compression and scalable architecture makes it cost-effective, especially when dealing with large volumes of time-series data.
- Community and Ecosystem: As an open-source project with an active community, Druid is constantly evolving. There is extensive documentation, and numerous integrations with tools like Apache Kafka, Apache Flink, and various BI platforms.
Druid’s Architecture
Druid has a distributed architecture that is designed to be cloud-friendly and easy to operate. You can configure and scale services independently for maximum flexibility over cluster operations. This design includes enhanced fault tolerance: an outage of one component does not immediately affect other components.
The following diagram shows the services that make up the Druid architecture, their typical arrangement across servers, and how queries and data flow through this architecture.
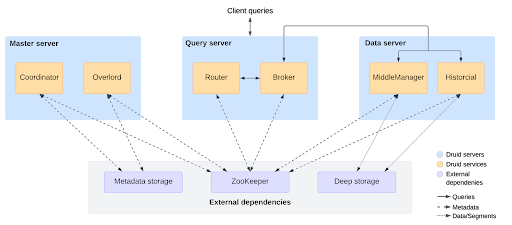
Druid has several types of services:
- Coordinator manages data availability on the cluster.
- Overlord controls the assignment of data ingestion workloads.
- Broker handles queries from external clients.
- Router routes requests to Brokers, Coordinators, and Overlords.
- Historical stores queryable data.
- MiddleManager and Peon ingest data.
- Indexer serves an alternative to the MiddleManager + Peon task execution system.
Ingestion in Apache Druid
Ingestion refers to the process of loading raw data into Druid and creating optimized segments. Druid supports multiple ingestion types (batch, streaming), allowing flexibility in how data is ingested and indexed.
Types of Ingestion:
- Batch Ingestion:
- Data is ingested in bulk from files (e.g., CSV, Parquet, ORC) or databases (using JDBC or Hadoop).
- Commonly used for historical or large datasets.
- Streaming Ingestion:
- Data is ingested continuously in real-time from data streams like Apache Kafka or Kinesis.
- Suitable for time-sensitive data, providing low-latency ingestion and querying.
Ingestion Spec Structure:
An ingestion specification (ingestion spec) defines how data should be ingested into Druid. Below is the structure of a typical ingestion spec:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
{ "type": "index", // Batch ingestion (use 'index_parallel' for parallel indexing) "spec": { "dataSchema": { "dataSource": "my_data_source", // Name of the datasource "granularitySpec": { "type": "uniform", // Time-based partitioning "segmentGranularity": "day", // Create segments per day "queryGranularity": "none", // No query-level aggregation "intervals": ["2023-01-01/2023-01-31"] // Time range of data }, "dimensionsSpec": { "dimensions": ["name", "age", "class"], // Dimensions in the data "metrics": ["count", "sum"] // Optional metrics } }, "ioConfig": { "type": "local", // Ingestion source (local file, hdfs, s3, etc.) "inputSource": { "type": "local", "baseDir": "/path/to/data/files", // Directory of data files "filter": "*.json" // File format }, "inputFormat": { "type": "json" // File format (CSV, Parquet, etc.) } }, "tuningConfig": { "type": "index", // Index tuning configurations "maxRowsInMemory": 1000000, // Rows to process in memory "maxBytesInMemory": 1000000000, // Maximum memory usage "forceExtendableShardSpecs": true // Enables dynamic segment creation } } } |
Performance Optimization techniques for Apache Druid
1. Data Partitioning
- Segment Granularity: Set appropriate segment granularity (e.g., hour, day, month) based on query patterns. Smaller granularities result in fewer rows scanned for time-bound queries.
- Sharding: Use hash-based or range-based partitioning for data to improve query parallelization across multiple segments.
- Data Locality: Ensure segment distribution across the cluster is balanced to maximize parallelism.
2. Query Optimizations
-
- Pre-aggregations: Enable data roll-up during ingestion for common aggregations to reduce query time.
- Query Granularity: Use the most appropriate granularity (e.g., minute, hour, day) to reduce unnecessary data scans.
-
- Filter Usage: Apply filters early in the query to limit the data scanned by the system.
- Use GroupBy and TopN Queries Efficiently: These queries are optimized for different use cases. Use GroupBy for high-cardinality dimensions and TopN for low-cardinality queries.
3. Segment Optimization
- Compaction: Regularly compact smaller segments into larger ones to reduce the number of segments scanned in queries.
- Segment Size: Keep segment sizes between 300MB to 700MB to ensure efficient data distribution and avoid overhead of managing too many small segments.
- Compression: Use better compression techniques like LZ4 for faster decompression during queries, balancing storage and performance.
4. Indexing Strategies
- Bitmap Indexing: Use bitmap indexes for categorical or low-cardinality columns to speed up filtering.
- Dictionary Encoding: Druid encodes string columns as dictionaries, which saves space and improves lookup performance.
- Bloom Filters: Use bloom filters for columns with high-cardinality to reduce query time for matching specific values.
5. Hardware Considerations
- Memory Optimization: Ensure enough memory is allocated to historical nodes to cache segments and reduce disk I/O.
- SSD Usage: Use SSDs for faster data access and disk I/O for faster query processing.
- CPU Optimization: Scale CPU cores for brokers and historical nodes based on query load to enable parallel execution of queries.
6. Tuning Configurations
-
- Query Cache: Enable caching on brokers and historical nodes to serve repeated queries faster.
- Batch Ingestion: For bulk ingestion jobs, use batch mode to reduce ingestion time and improve resource usage.
- Max Rows in Memory: Tune maxRowsInMemory in tuningConfig for efficient memory usage during ingestion.
7. Concurrency Handling
- Segment Loading/Unloading: Optimize segment balancing strategies to ensure the system handles high concurrency without affecting query performance.
- Thread Pools: Tune the thread pools on the broker, historical, and real-time nodes to handle the desired level of concurrent queries.
8. Roll-up Strategy
- Data Roll-up: Aggregate similar data during ingestion to reduce the total data size and the number of rows processed during queries.
Conclusion
In the era of big data, businesses need databases that can not only store and process large volumes of data but also deliver insights quickly. Apache Druid, with its ability to handle both real-time and historical data, scalable architecture, and blazing-fast query performance, is a powerful solution for anyone needing real-time analytics. Whether you’re building dashboards, tracking user behavior, or managing a data warehouse, Druid is designed to handle the demanding needs of modern data-driven applications.
For more about Apache Druid visit Apache Druid Introduction and Snowflake vs Apache Druid comparison visit Snowflake vs Apache Druid.
Resources:
Related content

Auriga: Leveling Up for Enterprise Growth!
Auriga’s journey began in 2010 crafting products for India’s