Some of our featured work
Kapila Cattle Feed
Pine Labs
ICICI Prudential
Upvrd
Ferns N Petals
Equiplus India
Savewallets
LogIQids
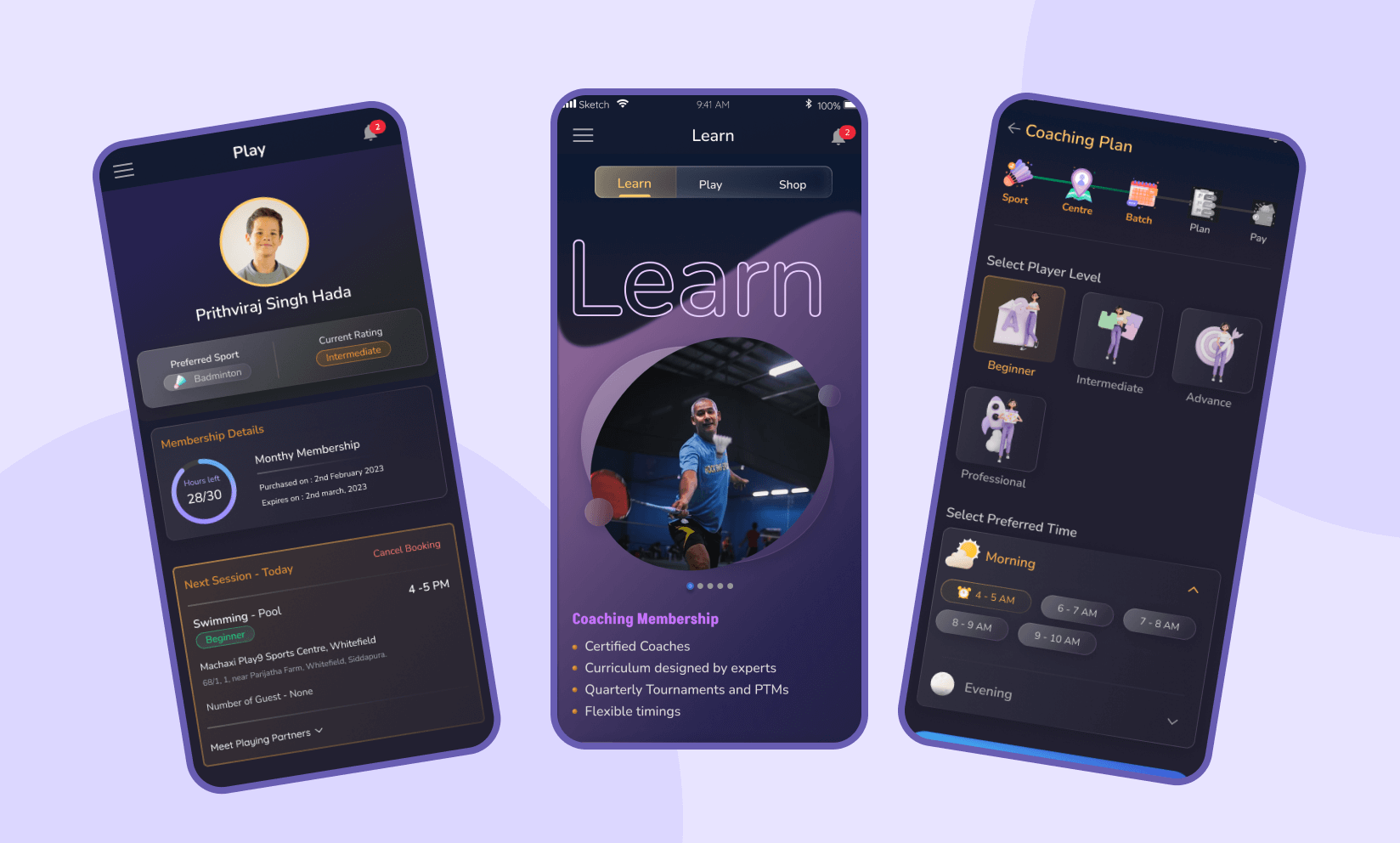
Machaxi
TR Capital
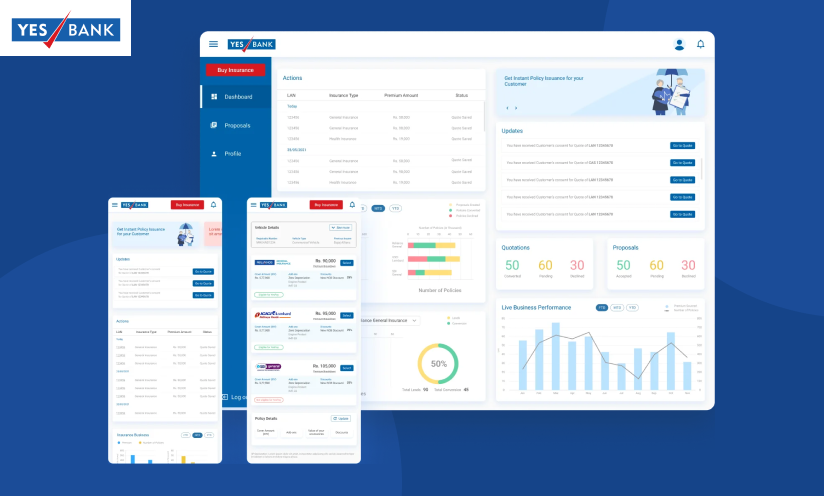
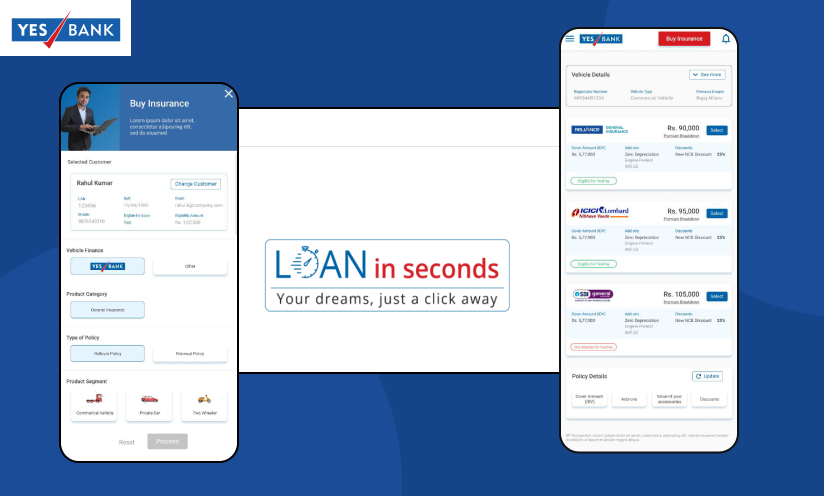
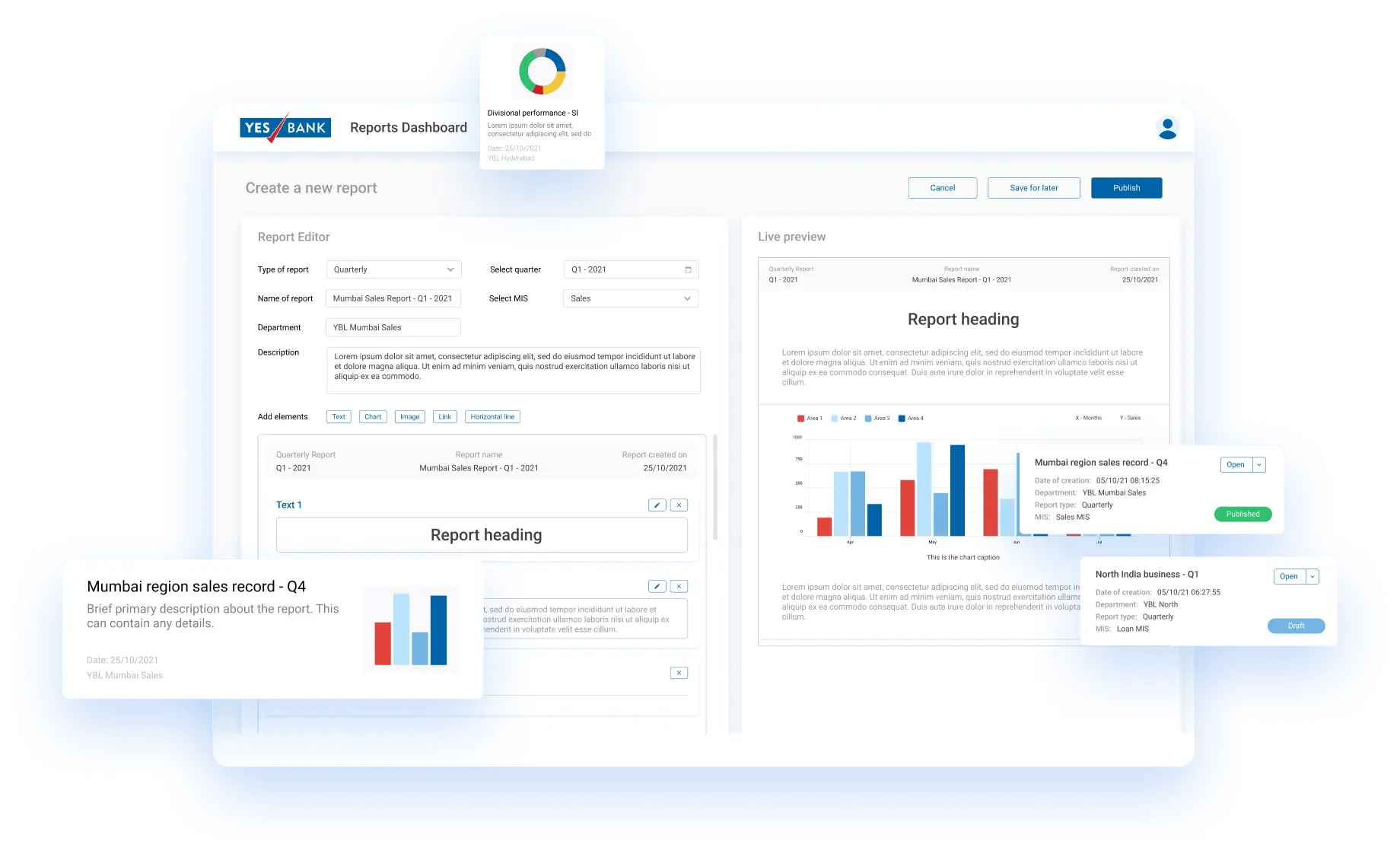
Yes Bank
PRADAN
MyNeta
RIAZ CAPITAL
Maheshwari Public School
Basant Industries
Tata Pay UPI
Angara Inc.
Taghive
RecoBee
Agrim
Samagra Governance Consulting
OTOO Tuition
evfin
GearX
Darwin Labs
DTRT Apparels
Colence Leather
GDi Partners
Prayagraj Smart City
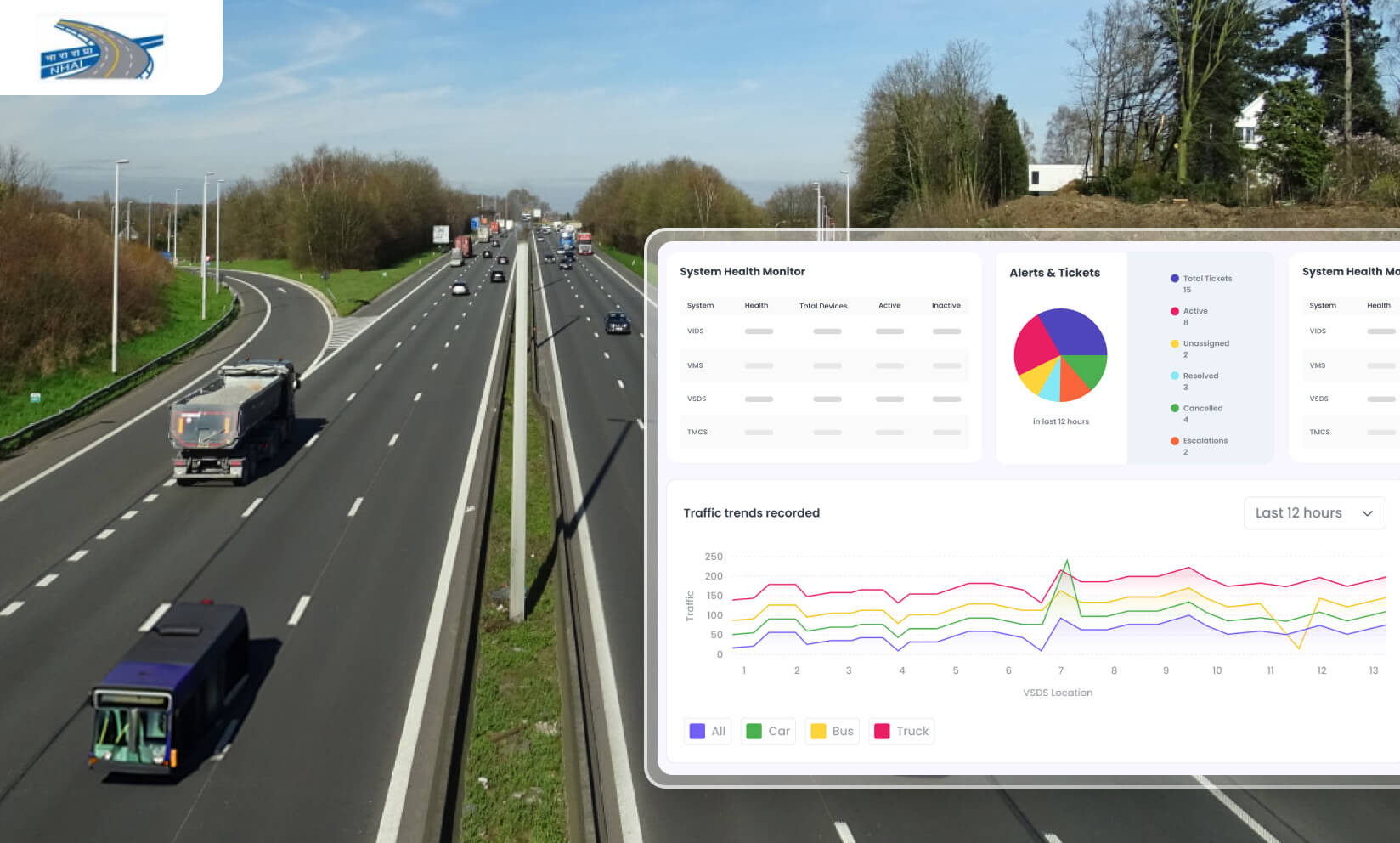
NHAI
Fooza Foods
Meesho
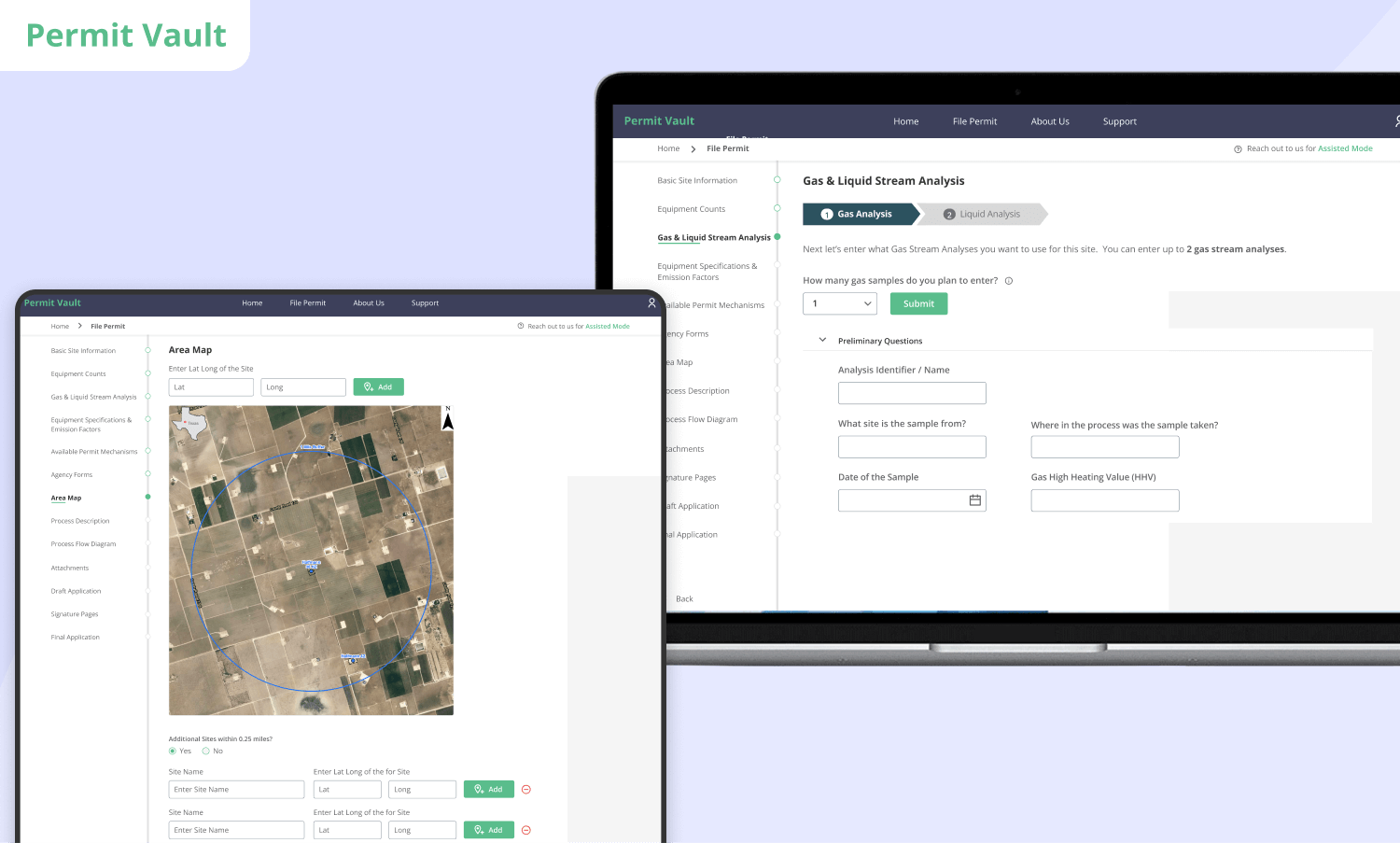
Permit Vault
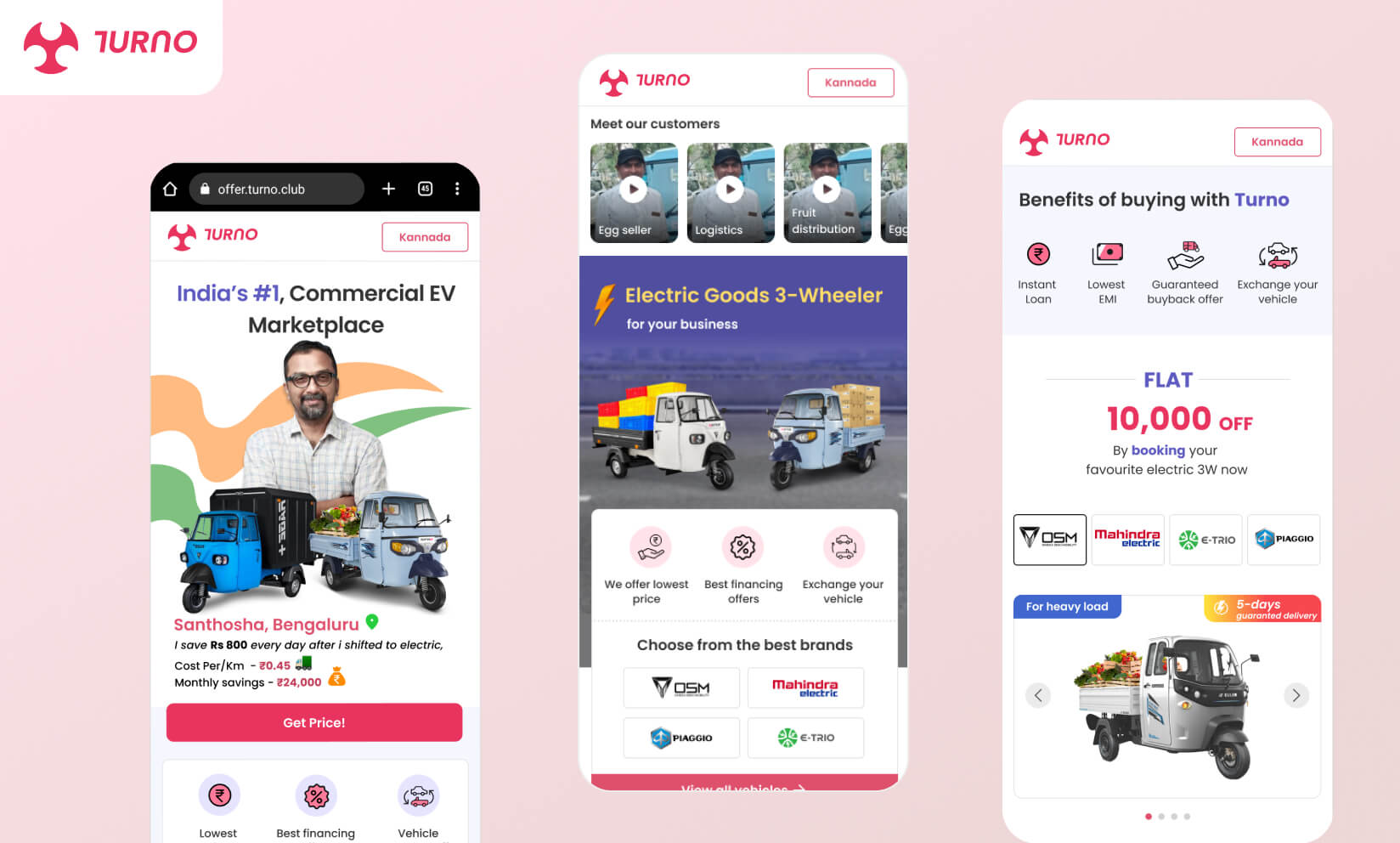
Turno
Meta
PineLabs
StepChange
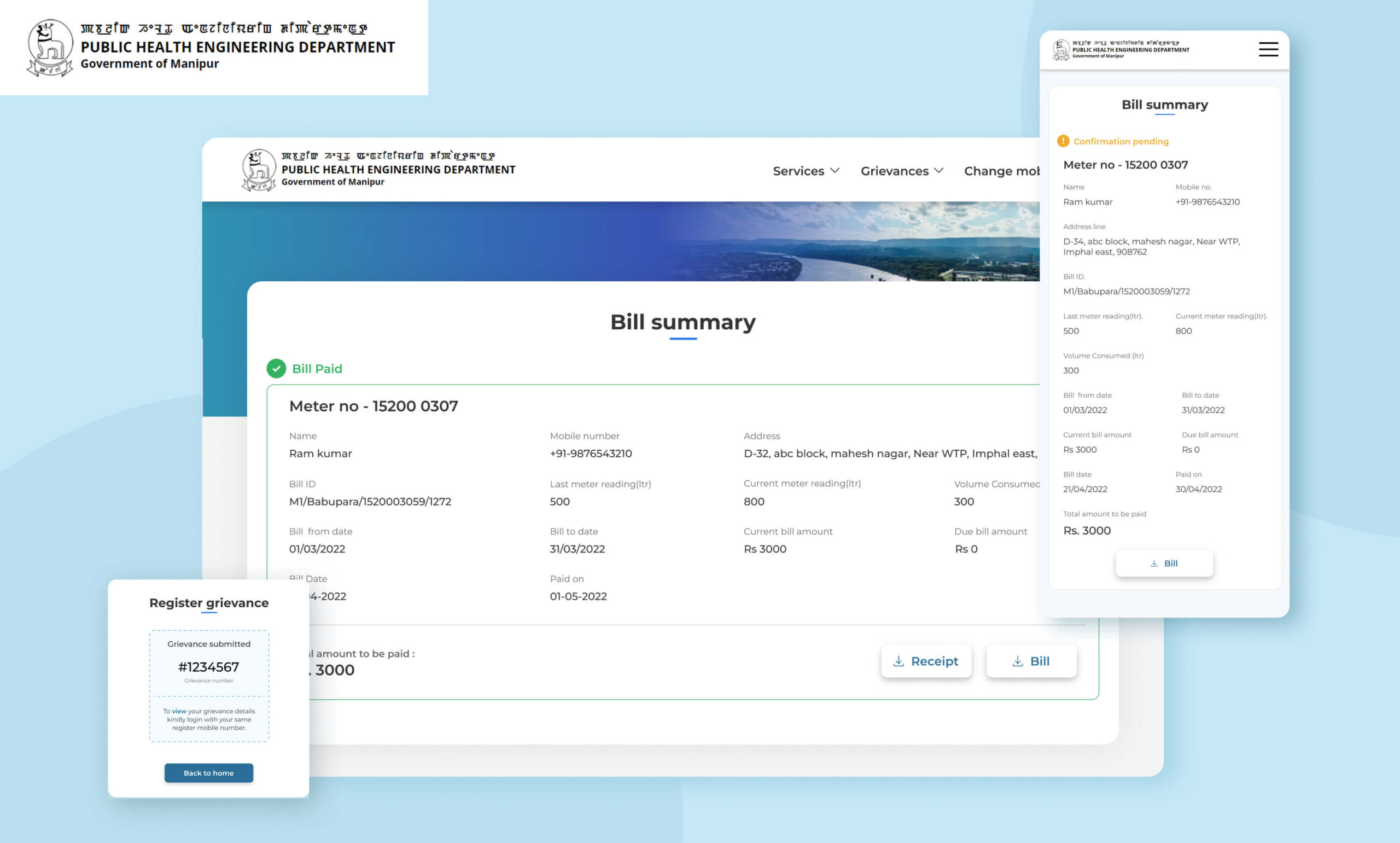
PHED Manipur
YesBank
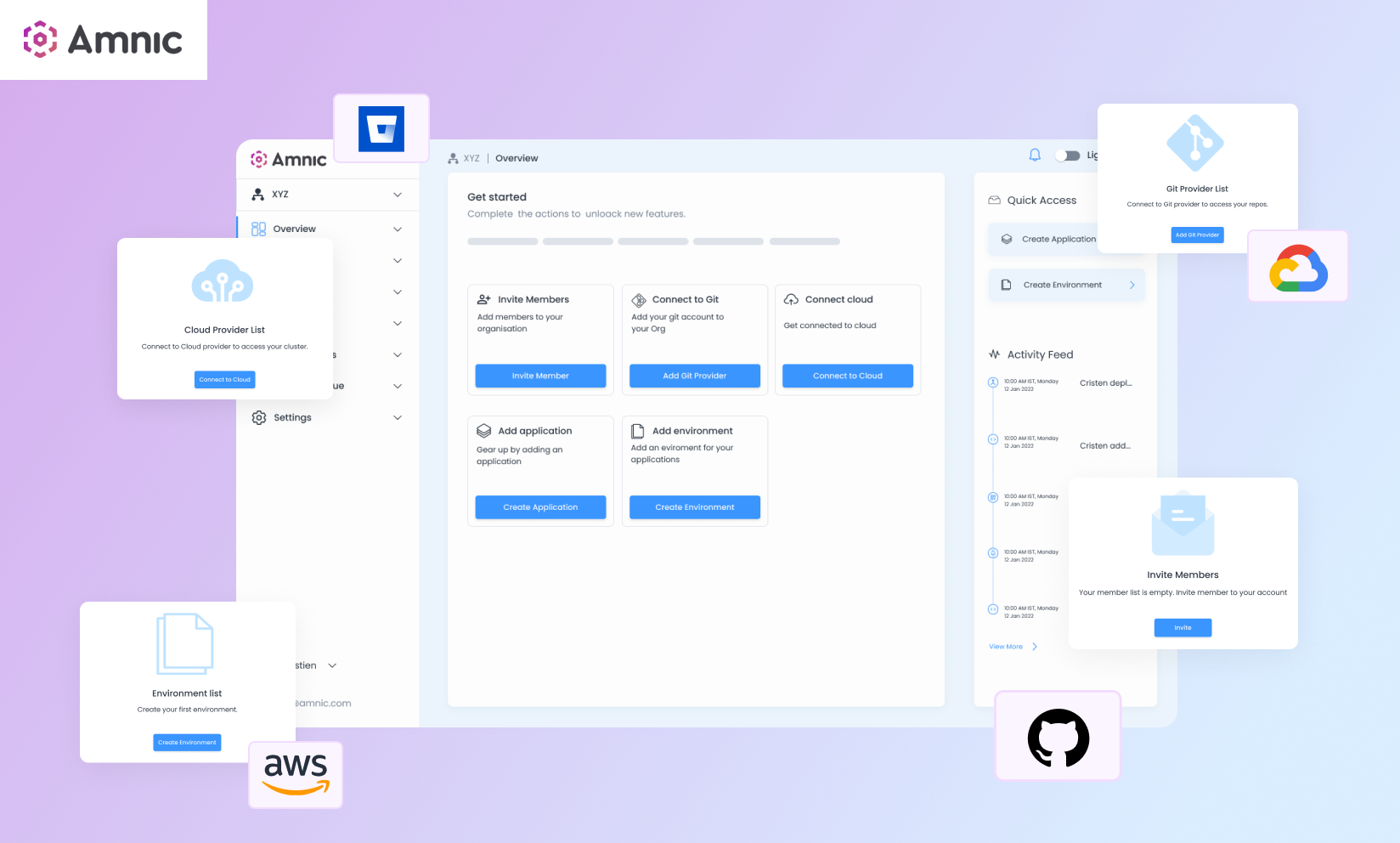
Amnic
Practo
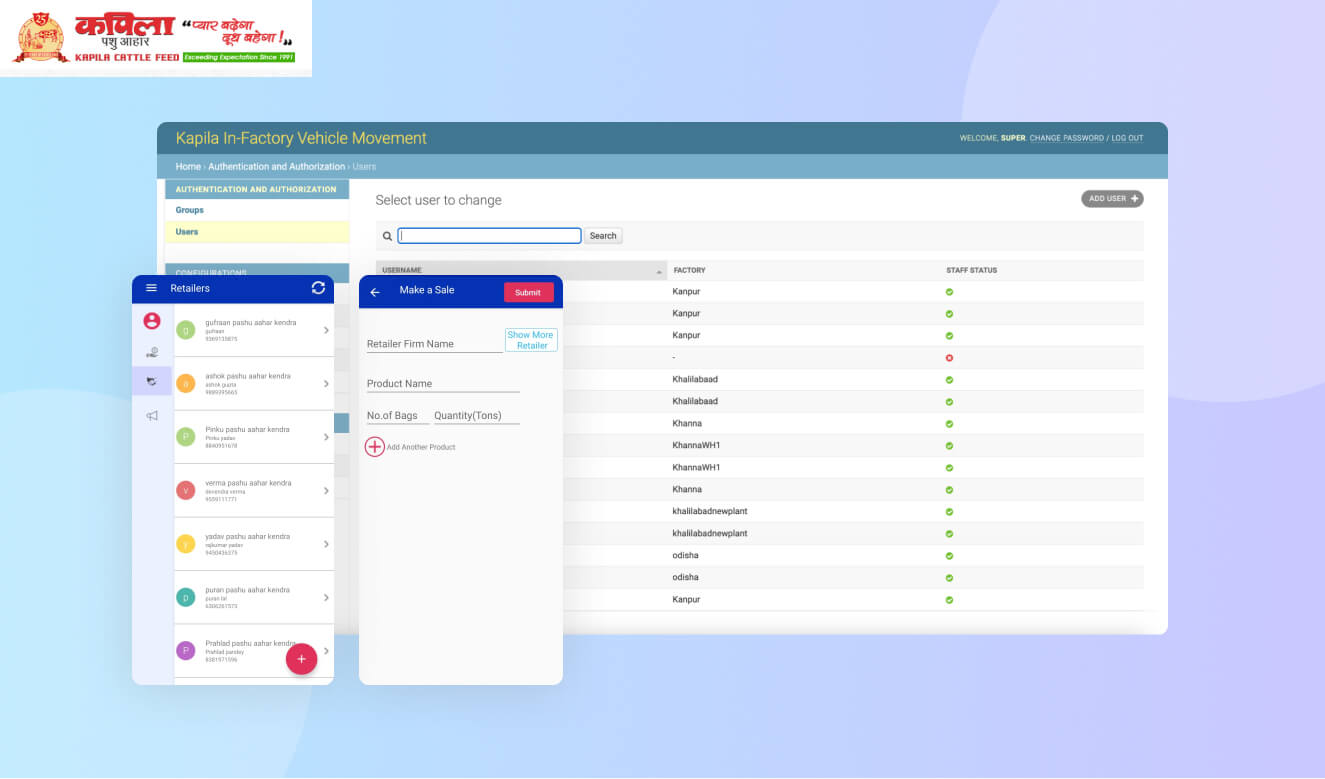
Kamdhenu Cattle Feed
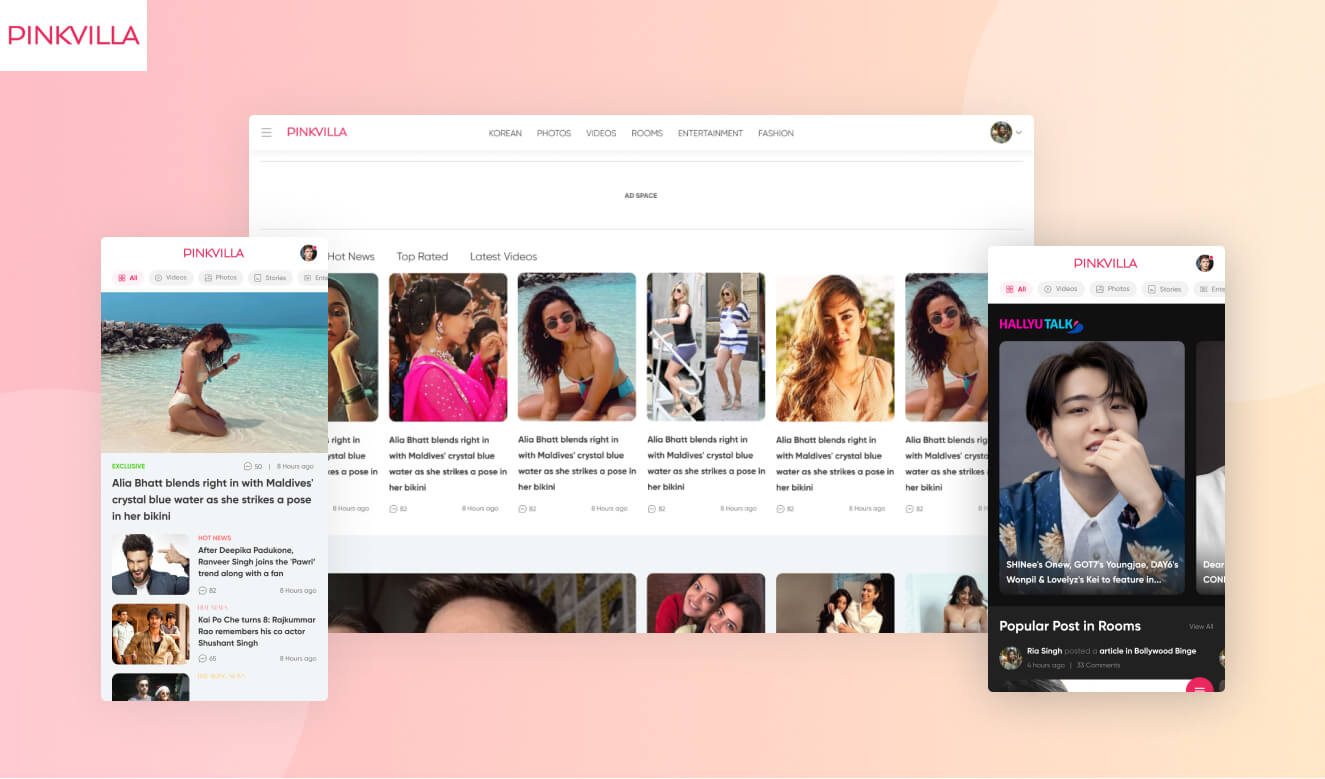
Pinkvilla
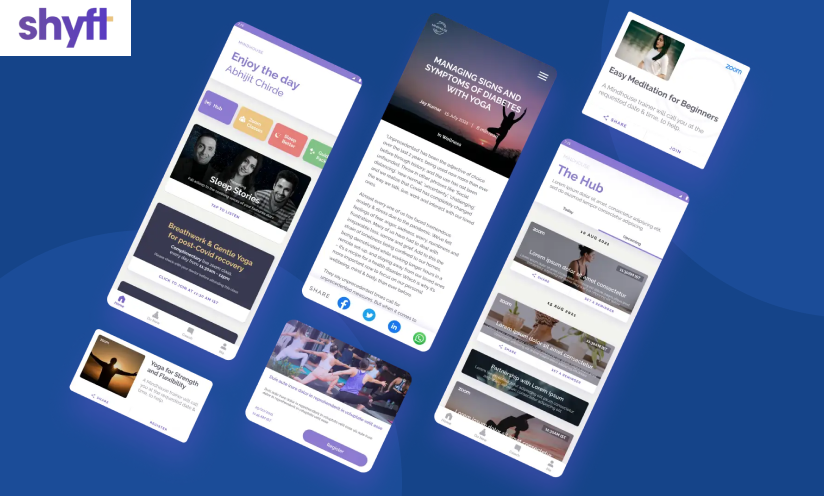
Shyft
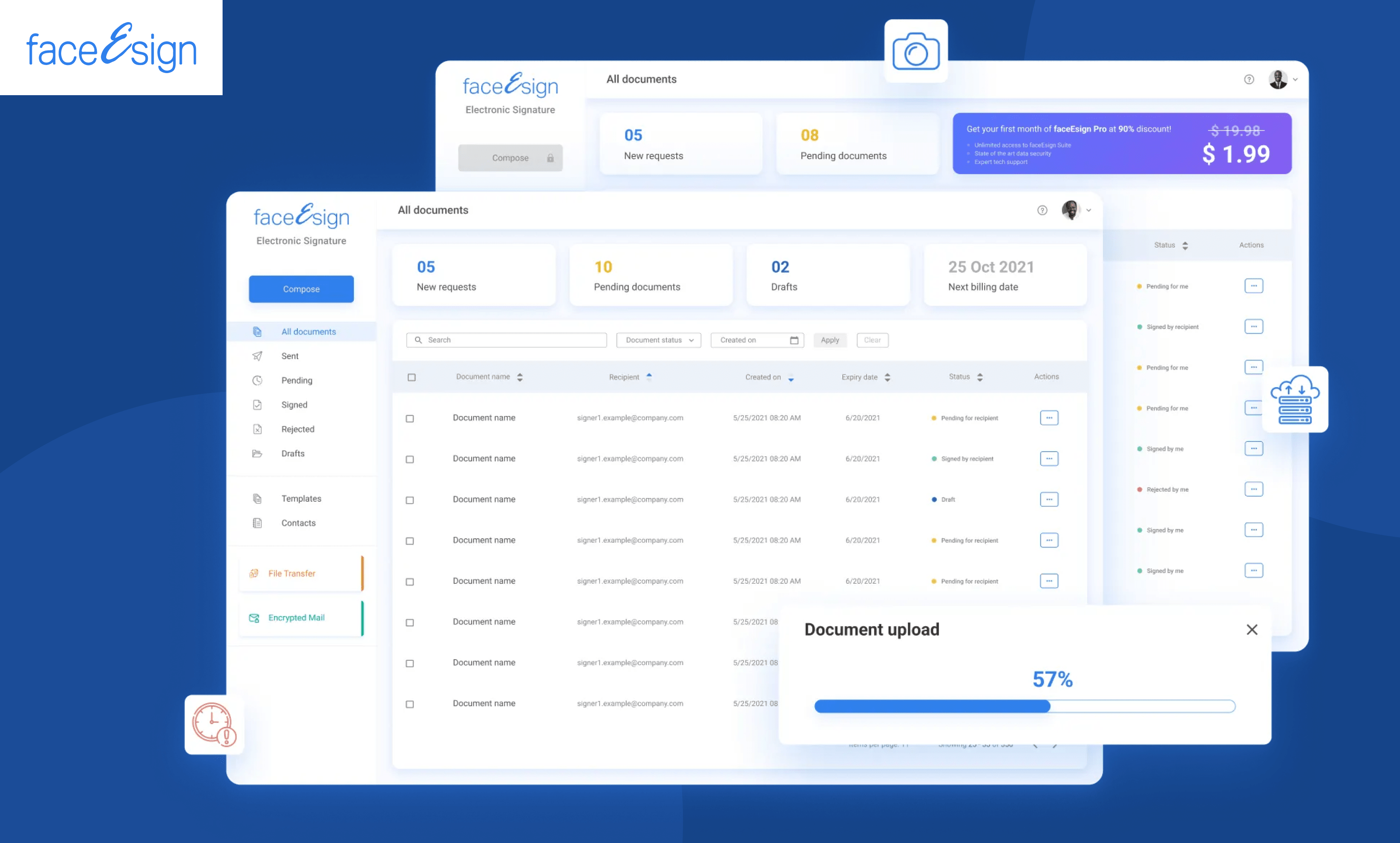
FaceESign
Scandinavian
RajCOMP Info Services Ltd.
Samagra
FaceEsign
Clear 360
Vedantu
Quizworks
SLA Financials
SaveIn
OpenTalk